This is the multi-page printable view of this section. Click here to print.
Documentation
- 1: Overview
- 2: Getting Started
- 3: How Tos
- 3.1: Configuring RAG
- 3.2: Use Anthropic
- 3.3: Use Azure OpenAI
- 3.4: Use Ollama
- 3.5: BigQuery
- 3.6: Honeycomb
- 3.7: Datadog
- 4: Operator Manual
- 4.1: Monitoring AI Quality
- 4.2: Troubleshoot Learning
- 4.3: Cloud Logging
- 4.4: Datadog
- 4.5: Honeycomb
- 5: Developer Guide
- 5.1: Documentation Guidelines
- 5.2: Evaluation
- 5.3: Adding Assertions
- 6: Blog
- The Unreasonable Effectiveness of Human Feedback
- Without a copilot for devops we won't keep up
- Logging Implicit Human Feedback
- 7: Tech Notes
- 7.1: TN001 Logging
- 7.2: TN002 Learning from Human Feedback
- 7.3: TN003 Learning Evaluation
- 7.4: TN004 Integration with Runme.Dev
- 7.5: TN005 Continuous Log Processing
- 7.6: TN006 Continuous Learning
- 7.7: TN007 Shared Learning
- 7.8: TN008 Auto Insert Cells
- 7.9: TN009 Review AI in Notebooks
- 7.10: TN010 Level 1 Evaluation
- 7.11: TN011 Building An Eval Dataset
- 7.12: TN012 Why Does Foyle Cost So Much
- 7.13: TN013 Improve Learning
1 - Overview
What is Foyle?
Foyle is an AI assistant integrated with VS Code notebooks, through the Runme extension. It helps you deploy and operate your application by letting you express your intent in natural language and then using AI to generate the commands to achieve that intent.
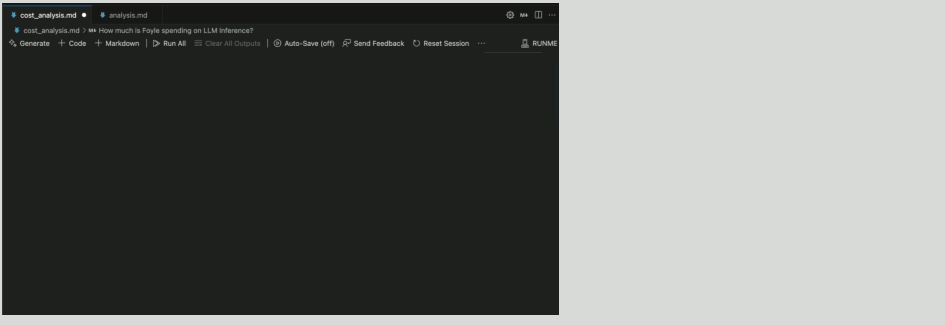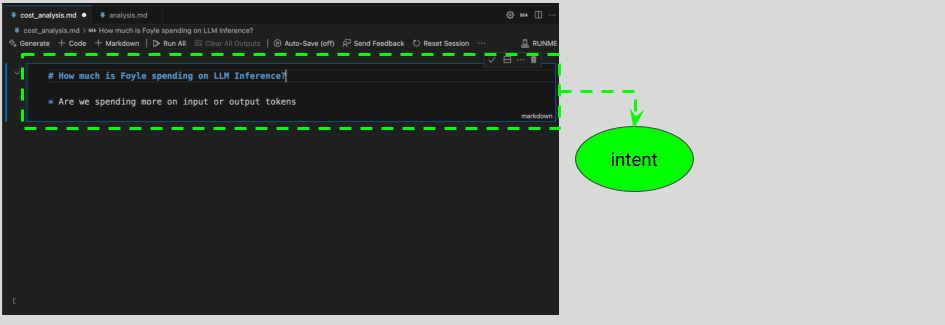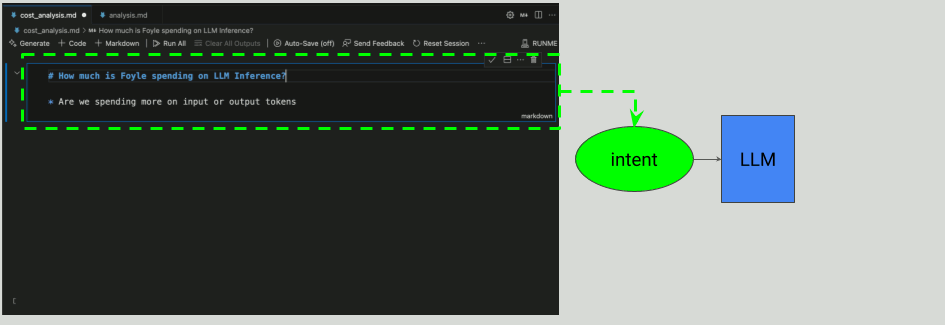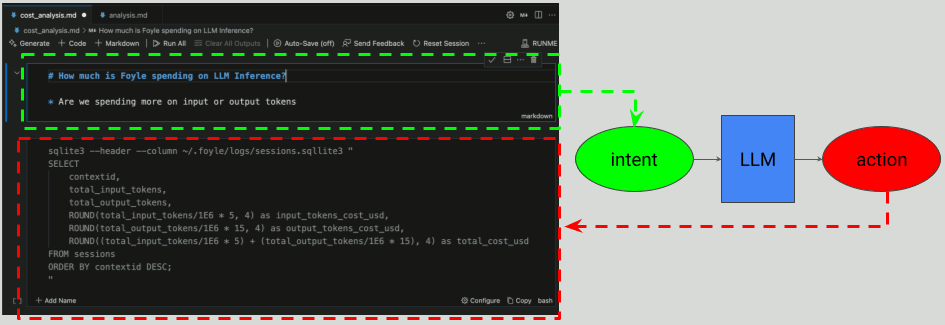
Why use Foyle?
- You struggle to remember complex commands and want to offload this problem to an AI
- You are tired of copy/pasting commands from ChatGPT/Claude/Bard into your shell
- You value documentation and want to produce markdown documents that capture
- The problem or question you are trying to solve
- The commands you ran to solve the problem
- The output of those commands
- Your analysis and conclusions
Who is Foyle for?
If your building or operating software, Foyle can help you. If your an individual developer, you can deploy Foyle locally. If you are a team, you can deploy Foyle on Kubernetes so that you have a shared AI that spreads knowledge among the team.
How much does Foyle cost?
Foyle itself is free to use. You will need to pay for your LLM usage by providing an API key or deploying your own LLM.
Where should I go next?
- Getting Started: Get started with $project
- FAQ: Frequently asked questions
2 - Getting Started
2.1 - Getting Started Locally
Deploying Foyle locally is the quickest, easiest way to try out Foyle.
Installation
Prerequisites: VSCode & RunMe
Foyle relies on VSCode and Runme.dev to provide the frontend.
- If you don’t have VSCode visit the downloads page and install it
- Follow Runme.dev instructions to install the RunMe.dev extension in vscode
Install Foyle
Download the latest release from the releases page
On Mac you may need to remove the quarantine attribute from the binary
xattr -d com.apple.quarantine /path/to/foyle
Setup
Configure your OpenAPI key
foyle config set openai.apiKeyFile=/path/to/openai/apikey- If you don’t have a key, go to OpenAI to obtain one
Start the server
foyle serveBy default foyle uses port 8877 for the http server
If you need to use a different port you can configure this as follows
foyle config set server.httpPort=<YOUR HTTP PORT>Inside VSCode configure RunMe to use Foyle
- Open the VSCode settings palette
- Search for
Runme > Experiments: Ai Auto Cell- Check the box to set the option to true
- Search for
Runme: Ai Base URL - Set the address to
http://localhost:${HTTP_PORT}/api- The default port is 8877
- If you set a non default value then it will be the value of
server.httpPort
Try it out!
Now that foyle is running you can open markdown documents in VSCode and start interacting with foyle.
Inside VSCode Open a markdown file or create a notebook; this will open the notebook inside RunMe
- Refer to RunMe’s documentation for a walk through of RunMe’s UI
- If the notebook doesn’t open in RunMe
- right click on the file and select “Open With”
- Select the option “Run your markdown” to open it with RunMe
You can now add code and notebook cells like you normally would in vscode
To ask Foyle for help do one of the following
- Open the command pallet and search for
Foyle generate a completion - Use the shortcut key:
- “win;” - on windows
- “cmd;” - on mac
- Open the command pallet and search for
Customizing Foyle VSCode Extension Settings
Customizing the Foyle Server Address
- Open the settings panel; you can click the gear icon in the lower left window and then select settings
- Search for `Runme: Ai base URL
- Set
Runme: Ai base URLto the address of the Foyle server to use as the Agent- The Agent handles requests to generate completions
Customizing the keybindings
If you are unhappy with the default key binding to generate a completion you can change it as follows
- Click the gear icon in the lower left window and then select “Keyboard shortcuts”
- Search for “Foyle”
- Change the keybinding for
Foyle: generate a completionto the keybinding you want to use
Where to go next
- Learning from feedback - How to improve the AI with human feedback.
2.2 - Deploying Foyle on Kubernetes
Deploying Foyle on Kubernetes is the recommended way for teams to have a shared instance that transfers knowledge across the organization.
Installation
Prerequisites: VSCode & RunMe
Foyle relies on VSCode and RunMe.dev to provide the frontend.
- If you don’t have VSCode visit the downloads page and install it
- Follow RunMe.dev instructions to install the RunMe.dev extension in vscode
Deploy Foyle on Kubernetes
Create the namespace foyle
kubectl create namespace foyle
Clone the foyle repository to download a copy of the kustomize package
git clone https://github.com/jlewi/foyle.git
Deploy foyle
cd foyle
kustomize build manifests | kubectl apply -f -
Create a secret with your OpenAI API key
kubectl create secret generic openai-key --from-file=openai.api.key=/PATH/TO/YOUR/OPENAI/APIKEY -n foyle
Verify its working
Check the pod is running
kubectl get pods -n foyle
NAME READY STATUS RESTARTS AGE
foyle-0 1/1 Running 0 58m
Port forward to the pod
kubectl -n foyle port-forward foyle-0 8877:8877
Verify the service is accessible and healthy
curl http://localhost:8877/healthz
{"server":"foyle","status":"healthy"}
Expose the service on your VPN
At this point you should customize the K8s service to make it accessible from employee machines over your VPN.
While you could use it via kubectl port-forward that isn’t a very good user experience.
If your looking for a VPN its hard to beat Tailscale.
Configure Runme
Inside VSCode configure Runme to use Foyle
- Open the VSCode setting palette
- Search for
Runme: Ai Base URL - Set the address to
http://${HOST}:${PORT}/api
- The value of host and port will depend on how you make it accessible over vpn
- The default port is 8877
3 - How Tos
3.1 - Configuring RAG
What You’ll Learn
How to configure Learning in Foyle to continually learn from human feedback
How It Works
- As you use Foyle, the AI builds a dataset of examples (input, output)
- The input is a notebook at some point in time ,
t - The output is one more or cells that were then added to the notebook at time
t+1 - Foyle uses these examples to get better at suggesting cells to insert into the notebook
Configuring RAG
Foyle uses RAG to improve its predictions using its existing dataset of examples. You can control
the number of RAG results used by Foyle by setting agent.rag.maxResults.
foyle config set agent.rag.maxResults=3
Disabling RAG
RAG is enabled by default. To disable it run
foyle config set agent.rag.enabled=false
To check the status of RAG get the current configuration
foyle config get
Sharing Learned Examples
In a team setting, you should build a shared AI that learns from the feedback of all team members and assists all members. To do this you can configure Foyle to write and read examples from a shared location like GCS. If you’d like S3 support please vote up issue #153.
To configure Foyle to use a shared location for learned examples
Create a GCS bucket to store the learned examples
gsutil mb gs://my-foyle-examplesConfigure Foyle to use the GCS bucket
foyle config set learner.exampleDirs=gs://${YOUR_BUCKET}
Optionally you can configure Foyle to use a local location as well if you want to be able to use the AI without an internet connection.
foyle config set learner.exampleDirs=gs://${YOUR_BUCKET},/local/training/examples
3.2 - Use Anthropic
What You’ll Learn
How to configure Foyle to use Anthropic Models
Prerequisites
- You need a Anthropic account
Setup Foyle To Use Anthropic Models
Get an API Token from the Anthropic Console and save it to a file
Configure Foyle to use this API key
foyle config set anthropic.apiKeyFile=/path/to/your/key/file
- Configure Foyle to use the desired Antrhopic Model
foyle config set agent.model=claude-3-5-sonnet-20240620
foyle config set agent.modelProvider=anthropic
How It Works
Foyle uses 2 Models
- A Chat model to generate completions
- An embedding model to compute embeddings for RAG
Anthropic doesn’t provide embedding models so Foyle continues to use OpenAI for the embedding models. At some, we may add support for Voyage AI’s embedding models.
3.3 - Use Azure OpenAI
What You’ll Learn
How to configure Foyle to use Azure OpenAI
Prerequisites
- You need an Azure Account (Subscription)
- You need access to Azure Open AI
Setup Azure OpenAI
You need the following Azure OpenAI resources:
Azure Resource Group - This will be an Azure resource group that contains your Azure OpenAI resources
Azure OpenAI Resource Group - This will contain your Azure OpenAI model deployments
You can use the Azure CLI to check if you have the required resources
az cognitiveservices account list --output=table Kind Location Name ResourceGroup ------ ---------- -------------- ---------------- OpenAI eastus ResourceName ResourceGroupNote You can use the pricing page to see which models are available in a given region. Not all models are available an all regions so you need to select a region with the models you want to use with Foyle.
Foyle currently uses gpt-3.5-turbo-0125
A GPT3.5 deployment
Use the CLI to list your current deployments
az cognitiveservices account deployment list -g ${RESOURCEGROUP} -n ${RESOURCENAME} --output=tableIf you need to create a deployment follow the instructions
Setup Foyle To Use Azure Open AI
Set the Azure Open AI BaseURL
We need to configure Foyle to use the appropriate Azure OpenAI endpoint. You can use the CLI to determine the endpoint associated with your resource group
az cognitiveservices account show \
--name <myResourceName> \
--resource-group <myResourceGroupName> \
| jq -r .properties.endpoint
Update the baseURL in your Foyle configuration
foyle config set azureOpenAI.baseURL=https://endpoint-for-Azure-OpenAI
Set the Azure Open AI API Key
Use the CLI to obtain the API key for your Azure OpenAI resource and save it to a file
az cognitiveservices account keys list \
--name <myResourceName> \
--resource-group <myResourceGroupName> \
| jq -r .key1 > ${HOME}/secrets/azureopenai.key
Next, configure Foyle to use this API key
foyle config set azureOpenAI.apiKeyFile=/path/to/your/key/file
Specify model deployments
You need to configure Foyle to use the appropriate Azure deployments for the models Foyle uses.
Start by using the Azure CLI to list your deployments
az cognitiveservices account deployment list --name=${RESOURCE_NAME} --resource-group=${RESOURCE_GROUP} --output=table
Configure Foyle to use the appropriate deployments
foyle config set azureOpenAI.deployments=gpt-3.5-turbo-0125=<YOUR-GPT3.5-DEPLOYMENT-NAME>
Troubleshooting:
Rate Limits
If Foyle is returning rate limiting errors from Azure OpenAI, use the CLI to check the rate limits for your deployments
az cognitiveservices account deployment list -g ${RESOURCEGROUP} -n ${RESOURCENAME}
Azure OpenAI sets the default values to be quite low; 1K tokens per minute. This is usually much lower than your allotted quota. If you have available quota, you can use the UI or to increase these limits.
3.4 - Use Ollama
What You’ll Learn
How to configure Foyle to use models served by Ollama
Prerequisites
- Follow [Ollama’s docs] to download Ollama and serve a model like
llama2
Setup Foyle to use Ollama
Foyle relies on Ollama’s OpenAI Chat Compatability API to interact with models served by Ollama.
Configure Foyle to use the appropriate Ollama baseURL
foyle config set openai.baseURL=http://localhost:11434/v1- Change the server and port to match how you are serving Ollama
- You may also need to change the scheme to https; e.g. if you are using a VPN like Tailscale
Configure Foyle to use the appropriate Ollama model
foyle config agent.model=llama2- Change the model to match the model you are serving with Ollama
You can leave the
apiKeyFileunset since you aren’t using an API key with OllamaThat’s it! You should now be able to use Foyle with Ollama
3.5 - BigQuery
Why Use Foyle with BigQuery
If you are using BigQuery as your data warehouse then you’ll want to query that data. Constructing the right query is often a barrier to leveraging that data. Using Foyle you can train a personalized AI assistant to be an expert in answering high level questions using your data warehouse.
Prerequisites
Install the Data TableRenderers extension in vscode
- This extension can render notebook outputs as tables
- In particular, this extension can render JSON as nicely formatted, interactive tables
How to integrate BigQuery with RunMe
Below is an example code cell illustrating the recommended pattern for executing BigQuery queries within RunMe.
cat <<EOF >/tmp/query.sql
SELECT
DATE(created_at) AS date,
COUNT(*) AS pr_count
FROM
\`githubarchive.month.202406\`
WHERE
type = "PullRequestEvent"
AND
repo.name = "jlewi/foyle"
AND
json_value(payload, "$.action") = "closed"
AND
DATE(created_at) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 28 DAY) AND CURRENT_DATE()
GROUP BY
date
ORDER BY
date;
EOF
export QUERY=$(cat /tmp/query.sql)
bq query --format=json --use_legacy_sql=false "$QUERY"
As illustrated above, the pattern is to use cat to write the query to a file. This allows
us to write the query in a more human readable format. Including the entire SQL query in the code
cell is critical for enabling Foyle to learn the query.
The output is formatted as JSON. This allows the output to be rendered using the Data TableRenderers extension.
Before executing the code cell click the configure button in the lower right hand side of the cell and then uncheck the box under “interactive”. Running the cell in interactive mode prevents the output from being rendered using Data TableRenders. For more information refer to the RunMe Cell Configuration Documentation.
We then use bq query to execute the query.
Controlling Costs
BigQuery charges based on the amount of data scanned. To prevent accidentally running expensive queries you can
use the --maximum_bytes_billed to limit the amount of data scanned. BigQuery currently charges
$6.25 per TiB.
Troubleshooting
Output Isn’t Rendered Using Data TableRenderers
If the output isn’t rendered using Data TableRenderers there are a few things to check
Click the ellipsis to the left of the the upper left hand corner and select change presentation
- This should show you different mime-types and options for rendering them
- Select Data table
Another problem could be that
bqis outputting status information while running the query and this is interfering with the rendering. You can work around this by redirecting stderr to/dev/null. For example,bq query --format=json --use_legacy_sql=false "$QUERY" 2>/dev/nullTry explicitly configuring the mime type by opening the cell configuration and then
- Go to the advanced tab
- Entering “application/json” in the mime type field
3.6 - Honeycomb
Why Use Honeycomb with Foyle
Honeycomb is often used to query and visualize observability data.
Using Foyle and RunMe you can
- Use AI to turn a high level intent into an actual Honeycomb query
- Capture that query as part of a playbook or incident report
- Create documents that capture the specific queries you are interested in rather than rely on static dashboards
How to integrate Honeycomb with Runne
This section explains how to integrate executing Honeycomb queries from Runme.
Honeycomb supports embedding queries directly in the URL. You can use this feature to define queries in your notebook and then generate a URL that can be opened in the browser to view the results.
Honeycomb queries are defined in JSON. A suggested pattern to define queries in your notebook are
- Create a code cell which uses contains the query to be executed
- To make it readable the recommended pattern is to treat it as a multi-line JSON string and write it to a file
- Use the CLI hccli to generate the URL and open it in the browser
- While the CLI allows passing the query as an argument this isn’t nearly as human readable as writing it and reading it from a temporary file Here’s an example code cell
cat << EOF > /tmp/query3.json
{
"time_range": 604800,
"granularity": 0,
"calculations": [
{
"op": "AVG",
"column": "prediction.ok"
}
],
"filters": [
{
"column": "model.name",
"op": "=",
"value": "llama3"
}
],
"filter_combination": "AND",
"havings": [],
"limit": 1000
}
EOF
hccli querytourl --query-file=/tmp/query3.json --base-url=https://ui.honeycomb.io/YOURORG/environments/production --dataset=YOURDATASET --open=true
- This is a simple query to get the average of the
prediction.okcolumn for thellama3model for the last week - Be sure to replace
YOURORGandYOURDATASETwith the appropriate values for your organization and dataset- You can determine
base-urljust by opening up any existing query in Honeycomb and copying the URL
- You can determine
- When you execute the cell, it will print the query and open it in your browser
- You can use the share query feature to encode the query in the URL
Training Foyle to be your Honeycomb Expert
To train Foyle to be your Honeycomb you follow these steps
- Create a markdown cell expressing the high level intent you want to accomplish
- Create a code cell which uses
hcclito generate the query link - Execute the code cell
- Foyle automatically learns how to predict every successfully executed code cell
If you need help boostrapping some initial Honeycomb JSON queries you can use Honeycomb’s Share feature to generate the JSON from a query constructed in the UI.
Producing Reports
RunMe’s AutoSave Feature creates a markdown document that contains the output of the code cells. This is great for producing a report or writing a postmortem. When using this feature with Honeycomb you’ll want to capture the output of the query. There are a couple ways to do this
Permalinks
To generate permalinks, you just need to use can use start_time and
end_time to specify a fixed time range for your queries (see Honeycomb query API). Since the
hccli prints the output URL it will be saved in the session outputs generated
by RunMe. You could also copy and past the URL into a markdown cell.
Grabbing a Screenshot
Unfortunately a Honeycomb enterprise plan is required to access query results and graphs via API. As a workaround, hccli supports grabbing a screenshot of the query results using browser automation.
You can do this as follows
Restart chrome with a debugging port open
chrome --remote-debugging-port=9222Login into Honeycomb
Add the
--out-file=/path/to/file.pngtohcclito specify a file to save it tohccli querytourl --query-file=/tmp/query3.json --base-url=https://ui.honeycomb.io/YOURORG/environments/production --dataset=YOURDATASET --open=true --out-file=/path/to/file.png
Warning Unfortunately this tends to be a bit brittle for the following reasons
You need to restart chrome with remote debugging enabled
hccliwill use the most recent browser window so you need to make sure your most recent browser window is the one with your Honeycomb credentials. This may not be the case if you have different accounts logged into different chrome sessions
Reference
3.7 - Datadog
Why Use Datadog with Foyle
Datadog is often used to store and visualize observability data.
Using Foyle and RunMe you can
- Use AI to turn a high level intent into an actual Datadog query or dashboard
- Capture that query as part of a playbook or incident report
- Create documents that capture the specific queries you are interested in rather than rely on static dashboards
How to integrate Datadog Logs with Runme
This section explains how to integrate Datadog Logs with Runme
Datadog supports embedding queries directly in the URL. You can use this feature to define log queries in your notebook and then generate a URL that can be opened in the browser to view the results. The ddctl CLI makes it easy to generate links.
Download the latest CLI from ddctl’s releases page
Configure it with the base URL for your Datadog instance
ddctl config set baseURL=https://acme.datadoghq.com- You can determine the baseURL by opening up the Datadog UI a
Create a code cell which uses contains the query to be executed
- To make it readable the recommended pattern is to treat it as a multi-line JSON string and write it to a file
Use the CLI ddctl to generate the URL and open it in the browser
- While the CLI allows passing the query as an argument this isn’t nearly as human readable as writing it and reading it from a temporary file Here’s an example code cell
cat << EOF > /tmp/query.yaml
query: service:foyle @contextId:01JEF30XB9A
EOF
ddctl logs querytourl --query-file=/tmp/query.yaml
The value of the YAML file should be a map containing the query arguments to include in the link
Some useful query arguments are
live: Set this to true if you always want to show the latest logs rather than fixing to a particular time range
You can use the
ddctlcommand line flags--durationand--end-timeto control the time window shown
Training Foyle to be your Datadog Expert
To train Foyle to be your Datadog expert you follow these steps
- Create a markdown cell expressing the high level intent you want to accomplish
- Create a code cell which uses
ddctlto generate the logs explorer link - Execute the code cell
- Foyle automatically learns how to predict every successfully executed code cell
4 - Operator Manual
This guide covers operating and troubleshooting Foyle.
4.1 - Monitoring AI Quality
What You’ll Learn
- How to observe the AI to understand why it generated the answers it did
What was the actual prompt and response?
A good place to start when trying to understand the AI’s responses is to look at the actual prompt and response from the LLM that produced the cell.
You can fetch the request and response as follows
- Get the log for a given cell
- From the cell get the traceId of the AI generation request
CELLID=01J7KQPBYCT9VM2KFBY48JC7J0
export TRACEID=$(curl -s -X POST http://localhost:8877/api/foyle.logs.LogsService/GetBlockLog -H "Content-Type: application/json" -d "{\"id\": \"${CELLID}\"}" | jq -r .blockLog.genTraceId)
echo TRACEID=$TRACEID
- Given the traceId, you can fetch the request and response from the LOGS
curl -s -o /tmp/response.json -X POST http://localhost:8877/api/foyle.logs.LogsService/GetLLMLogs -H "Content-Type: application/json" -d "{\"traceId\": \"${TRACEID}\"}"
CODE="$?"
if [ $CODE -ne 0 ]; then
echo "Error occurred while fetching LLM logs"
exit $CODE
fi
- You can view an HTML rendering of the prompt and response
- If you disable interactive mode for the cell then vscode will render the HTML respnse inline
- Note There appears to be a bug right now in the HTML rendering causing a bunch of newlines to be introduced relative to what’s in the actual markdown in the JSON request
jq -r '.requestHtml' /tmp/response.json > /tmp/request.html
cat /tmp/request.html
- To view the response
jq -r '.responseHtml' /tmp/response.json > /tmp/response.html
cat /tmp/response.html
- To view the JSON versions of the actual requests and response
jq -r '.requestJson' /tmp/response.json | jq .
jq -r '.responseJson' /tmp/response.json | jq '.messages[0].content[0].text'
- You can print the raw markdown of the prompt as follows
echo $(jq -r '.requestJson' /tmp/response.json | jq '.messages[0].content[0].text')
jq -r '.responseJson' /tmp/response.json | jq .
4.2 - Troubleshoot Learning
What You’ll Learn
- How to ensure learning is working and monitor learning
Check Examples
If Foyle is learning there should be example files in ${HOME}/.foyle/training
ls -la ~/.foyle/training
The output should include example.binpb files as illustrated below.
-rw-r--r-- 1 jlewi staff 9895 Aug 28 07:46 01J6CQ6N02T7J16RFEYCT8KYWP.example.binpb
If there aren’t any then no examples have been learned.
Trigger Learning
Foyle’s learning is triggered whenever a cell is successfully executed.
Every time you switch the cell in focus, Foyle creates a new session. The current session ID is displayed in the lower right hand context window in vscode.
You can use the session ID to track whether learning occured.
Did The Session Get Created
- Check the session log
CONTEXTID=01J7S3QZMS5F742JFPWZDCTVRG
curl -s -X POST http://localhost:8877/api/foyle.logs.SessionsService/GetSession -H "Content-Type: application/json" -d "{\"contextId\": \"${CONTEXTID}\"}" | jq .
If this returns not found then no log was created for this sessions and there is a problem with Log Processing
The output should include
- LogEvent for cell execution
- LogEvent for session end
- FullContext containing a notebook
Ensure the cells all have IDs
Did we try to create an example from any cells?
- If Foyle tries to learn from a cell it logs a message here
- We can query for that log as follows
jq -c 'select(.message == "Found new training example")' ${LASTLOG}
- If that returns nothing then we know Foyle never tried to learn from any cells
- If it returns something then we know Foyle tried to learn from a cell but it may have failed
- If there is an error processing an example it gets logged here
- So we can search for that error message in the logs
jq -c 'select(.level == "Failed to write example")' ${LASTLOG}
jq -c 'select(.level == "error" and .message == "Failed to write example")' ${LASTLOG}
Ensure Block Logs are being created
- The query below checks that block logs are being created.
- If no logs are being processed than there is a problem with the block log processing.
jq -c 'select(.message == "Building block log")' ${LASTLOG}
Check Prometheus counters
Check to make sure blocks are being enqueued for learner processing
curl -s http://localhost:8877/metrics | grep learner_enqueued_total
- If the number is 0 please open an issue in GitHub because there is most likely a bug
Check the metrics for post processing of blocks
curl -s http://localhost:8877/metrics | grep learner_sessions_processed
- The value of
learner_sessions_processed{status="learn"}is the number of blocks that contributed to learning - The value of
learner_sessions_processed{status="unexecuted"}is the number of blocks that were ignored because they were not executed
4.3 - Cloud Logging
What You’ll Learn
How to use Google Cloud Logging to monitor Foyle.
Google Cloud Logging
If you are running Foyle locally but want to stream logs to Cloud Logging you can edit the logging stanza in your config as follows:
logging:
sinks:
- json: true
path: gcplogs:///projects/${PROJECT}/logs/foyle
Remember to substitute in your actual project for ${PROJECT}.
In the Google Cloud Console you can find the logs using the query
logName = "projects/${PROJECT}/logs/foyle"
While Foyle logs to JSON files, Google Cloud Logging is convenient for querying and viewing your logs.
Logging to Standard Error
If you want to log to standard error you can set the logging stanza in your config as follows:
logging:
sinks:
- json: false
path: stderr
4.4 - Datadog
What You’ll Learn
How to use Datadog to monitor Foyle.
Datadog Logging
If you are running Foyle in a Kubernetes cluster with the Datadog agent then you can do the following to have your logs show up in Datadog.
Add Datadog’s universal tagging labels to the Foyle statefulset and the pod template e.g
labels:
tags.datadoghq.com/env: staging
tags.datadoghq.com/service: foyle
tags.datadoghq.com/version: "0.1"
Modify your logging configuration to tell Foyle to use the “level” field to store the logging
level. Ensure that json is set to true.
logging:
level: info
...
# Specify the names of the fields to match what Datadog uses
# https://docs.datadoghq.com/logs/log_configuration/parsing/?tab=matchers
logFields:
level: level
sinks:
- json: true
Prometheus (OpenMetrics)
To configure Datadog to scrape Foyle’s OpenMetrics (Prometheus endpoint) add the annotation for the OpenMetrics check to the annotations of the pod template spec
apiVersion: apps/v1
kind: StatefulSet
spec:
...
template:
metadata:
annotations:
ad.datadoghq.com/foyle.checks: |
{
"openmetrics": {
"init_config": {},
"instances": [
{
"openmetrics_endpoint": "http://%%host%%:%%port%%/metrics",
"namespace": "foyle",
"metrics": [".*"]
}
]
}
}
4.5 - Honeycomb
What You’ll Learn
- How to use Opentelemetry and Honeycomb To Monitor Foyle
Setup
Configure Foyle To Use Honeycomb
foyle config set telemetry.honeycomb.apiKeyFile = /path/to/apikey
Download Honeycomb CLI
- hccli is an unoffical CLI for Honeycomb.
- It is being developed to support using Honeycomb with Foyle.
TAG=$(curl -s https://api.github.com/repos/jlewi/hccli/releases/latest | jq -r '.tag_name')
# Remove the leading v because its not part of the binary name
TAGNOV=${TAG#v}
OS=$(uname -s | tr '[:upper:]' '[:lower:]')
ARCH=$(uname -m)
echo latest tag is $TAG
echo OS is $OS
echo Arch is $ARCH
LINK=https://github.com/jlewi/hccli/releases/download/${TAG}/hccli_${TAGNOV}_${OS}_${ARCH}
echo Downloading $LINK
wget $LINK -O /tmp/hccli
Move the hccli binary to a directory in your PATH.
chmod a+rx /tmp/hccli
sudo mv /tmp/hccli /tmp/hccli
On Darwin set the execute permission on the binary.
sudo xattr -d com.apple.quarantine /usr/local/bin/hccli
Configure Honeycomb
- In order for
hcclito generate links to the Honeycomb UI it needs to know base URL of your environment. - You can get this by looking at the URL in your browser when you are logged into Honeycomb.
- It is typically somethling like
https://ui.honeycomb.io/${TEAM}/environments/${ENVIRONMENT}
- You can set the base URL in your config
hccli config set baseURL=https://ui.honeycomb.io/${TEAM}/environments/${ENVIRONMENT}/
- You can check your configuration by running the get command
hccli config get
Measure Acceptance Rate
- To measure the utility of Foyle we can look at how often Foyle suggestions are accepted
- When a suggestion is accepted we send a LogEvent of type
ACCEPTED - This creates an OTEL trace with a span with name
LogEventand attributeeventType == ACCEPTED - We can use the query below to calculate the acceptance rate
QUERY='{
"calculations": [
{"op": "COUNT", "alias": "Event_Count"}
],
"filters": [
{"column": "name", "op": "=", "value": "LogEvent"},
{"column": "eventType", "op": "=", "value": "ACCEPTED"}
],
"time_range": 86400,
"order_by": [{"op": "COUNT", "order": "descending"}]
}'
hccli querytourl --dataset foyle --query "$QUERY" --open
Token Count Usage
- The cost of LLMs depends on the number of input and output tokens
- You can use the query below to look at token usage
QUERY='{
"calculations": [
{"op": "COUNT", "alias": "LLM_Calls_Per_Cell"},
{"op": "SUM", "column": "llm.input_tokens", "alias": "Input_Tokens_Per_Cell"},
{"op": "SUM", "column": "llm.output_tokens", "alias": "Output_Tokens_Per_Cell"}
],
"filters": [
{"column": "name", "op": "=", "value": "Complete"}
],
"breakdowns": ["trace.trace_id"],
"time_range": 86400,
"order_by": [{"op": "COUNT", "order": "descending"}]
}'
hccli querytourl --dataset foyle --query "$QUERY" --open
5 - Developer Guide
This guide is for developers looking to contribute to Foyle.
5.1 - Documentation Guidelines
We use Hugo to format and generate our website, the Docsy theme for styling and site structure, and Netlify to manage the deployment of the site. Hugo is an open-source static site generator that provides us with templates, content organisation in a standard directory structure, and a website generation engine. You write the pages in Markdown (or HTML if you want), and Hugo wraps them up into a website.
All submissions, including submissions by project members, require review. We use GitHub pull requests for this purpose. Consult GitHub Help for more information on using pull requests.
Quick start with Netlify
Here’s a quick guide to updating the docs. It assumes you’re familiar with the GitHub workflow and you’re happy to use the automated preview of your doc updates:
- Fork the Foyle repo on GitHub.
- Make your changes and send a pull request (PR).
- If you’re not yet ready for a review, add “WIP” to the PR name to indicate it’s a work in progress. (Don’t add the Hugo property “draft = true” to the page front matter, because that prevents the auto-deployment of the content preview described in the next point.)
- Wait for the automated PR workflow to do some checks. When it’s ready, you should see a comment like this: deploy/netlify — Deploy preview ready!
- Click Details to the right of “Deploy preview ready” to see a preview of your updates.
- Continue updating your doc and pushing your changes until you’re happy with the content.
- When you’re ready for a review, add a comment to the PR, and remove any “WIP” markers.
Updating a single page
If you’ve just spotted something you’d like to change while using the docs, we have a shortcut for you:
- Click Edit this page in the top right hand corner of the page.
- If you don’t already have an up to date fork of the project repo, you are prompted to get one - click Fork this repository and propose changes or Update your Fork to get an up to date version of the project to edit. The appropriate page in your fork is displayed in edit mode.
- Follow the rest of the Quick start with Netlify process above to make, preview, and propose your changes.
Previewing your changes locally
If you want to run your own local Hugo server to preview your changes as you work:
Follow the instructions in Getting started to install Hugo and any other tools you need. You’ll need at least Hugo version 0.45 (we recommend using the most recent available version), and it must be the extended version, which supports SCSS.
Fork the Foyle repo repo into your own project, then create a local copy using
git clone. Don’t forget to use--recurse-submodulesor you won’t pull down some of the code you need to generate a working site.git clone --recurse-submodules --depth 1 https://github.com/jlewi/foyle.gitRun
hugo serverin the site root directory. By default your site will be available at http://localhost:1313/. Now that you’re serving your site locally, Hugo will watch for changes to the content and automatically refresh your site.Continue with the usual GitHub workflow to edit files, commit them, push the changes up to your fork, and create a pull request.
Creating an issue
If you’ve found a problem in the docs, but you’re not sure how to fix it yourself, please create an issue in the Foyle repo. You can also create an issue about a specific page by clicking the Create Issue button in the top right hand corner of the page.
Useful resources
- Docsy user guide: All about Docsy, including how it manages navigation, look and feel, and multi-language support.
- Hugo documentation: Comprehensive reference for Hugo.
- Github Hello World!: A basic introduction to GitHub concepts and workflow.
5.2 - Evaluation
What You’ll Learn
- How to setup and run experiments to evaluate the quality of the AI responses in Foyle
Produce an evaluation dataset
In order to evaluate Foyle you need a dataset of examples that consist of notebooks and the expected cells to be appended to the notebook. If you’ve been using Foyle then you can produce a dataset of examples from the logs.
DATA_DIR=<Directory where you want to store the examples>
curl -X POST http://localhost:8877/api/foyle.logs.SessionsService/DumpExamples -H "Content-Type: application/json" -d "{\"output\": \"$DATA_DIR\"}"
This assumes you are running Foyle on the default port of 8877. If you are running Foyle on a different port you will need to adjust the URL accordingly.
Everytime you execute a cell it is logged to Foyle. Foyle turns this into an example where the input is all the cells in the notebook before the cell you executed and the output is the cell you executed. This allows us to evaluate how well Foyle does generating the executed cell given the preceding cells in the notebook.
Setup Foyle
Create a Foyle configuration with the parameters you want to test.
Create a directory to store the Foyle configuration.
make ${EXPERIMENTS_DIR}/${NAME}
Edit {EXPERIMENTS_DIR}/${NAME}/config.yaml to set the parameters you want to test; e.g.
- Assign a different port to the agent to avoid conflicting with other experiments or the production agent
- Configure the Model and Model Provider
- Configure RAG
Configure the Experiment
Create the file {$EXPERIMENTS_DIR}/${NAME}/config.yaml
kind: Experiment
apiVersion: foyle.io/v1alpha1
metadata:
name: "gpt35"
spec:
evalDir: <PATH/TO/DATA>
agentAddress: "http://localhost:<PORT>/api"
outputDB: "{$EXPERIMENTS_DIR}/${NAME}/results.sqlite"
- Set evalDir to the directory where you dumped the session to evaluation examples
- Set agentAddress to the address of the agent you want to evaluate
- Use the port you assigned to the agent in
config.yaml
- Use the port you assigned to the agent in
- Set outputDB to the path of the sqlite database to store the results in
Running the Experiment
Start an instance of the agent with the configuration you want to evaluate.
foyle serve --config=${EXPERIMENTS_DIR}/${NAME}/config.yaml
Run the experiment
foyle apply ${EXPERIMENTS_DIR}/${NAME}/experiment.yaml
Analyzing the Results
You can use sqlite to query the results.
The queries below compute the following
- The number of results in the dataset
- The number of results where an error prevented a response from being generated
- The distribution of the
cellsMatchResultfield in the results- A value of
MATCHindicates the generated cell matches the expected cell - A value of
MISMATCHindicates the generated cell doesn’t match the expected cell - A value of
""(empty string) indicates no value was computed most likely because an error occurred
- A value of
# Count the total number of results
sqlite3 --header --column ${RESULTSDB} "SELECT COUNT(*) FROM results"
# Count the number of errors
sqlite3 --header --column ${RESULTSDB} "SELECT COUNT(*) FROM results WHERE json_extract(proto_json, '$.error') IS NOT NULL"
# Group results by cellsMatchResult
sqlite3 --header --column ${RESULTSDB} "SELECT json_extract(proto_json, '$.cellsMatchResult') as match_result, COUNT(*) as count FROM results GROUP BY match_result"
You can use the following query to look at the errors
sqlite3 ${RESULTSDB} "SELECT
id,
json_extract(proto_json, '$.error') as error
FROM results WHERE json_extract(proto_json, '$.error') IS NOT NULL;"
5.3 - Adding Assertions
Adding Level 1 Evals
- Define the Assertion in eval/assertions.go
- Update Assertor in assertor.go to include the new assertion
- Update AssertRow proto to include the new assertion
- Update toAssertionRow to include the new assertion in `As
6 - Blog
Blogs related to Foyle.
The Unreasonable Effectiveness of Human Feedback
Agents! Agents! Agents! Everywhere we look we are bombarded with the promises of fully autonomous agents. These pesky humans aren’t merely inconveniences, they are budgetary line items to be optimized away. All this hype leaves me wondering; have we forgotten that GPT was fine-tuned using data produced by a small army of human labelers? Not to mention who do we think produced the 10 trillion words that foundation models are being trained on? While fully autonomous software agents are capturing the limelight on social media, systems that turn user interactions into training data like Didact, Dosu and Replit code repair are deployed and solving real toil.
Foyle takes a user-centered approach to building an AI to help developers deploy and operate their software. The key premise of Foyle is to instrument a developer’s workflow so that we can monitor how they turn intent into actions. Foyle uses that interaction data to constantly improve. A previous post described how Foyle uses this data to learn. This post presents quantitative results showing how feedback allows Foyle to assist with building and operating Foyle. In 79% of cases, Foyle provided the correct answer, whereas ChatGPT alone would lack sufficient context to achieve the intent. In particular, the results show how Foyle lets users express intent at a higher level of abstraction.
As a thought experiment, we can compare Foyle against an agentic approach that achieves the same accuracy by recursively invoking an LLM on Foyle’s (& RunMe’s) 65K lines of code but without the benefit of learning from user interactions. In this case, we estimate that Foyle could easily save between $2-$10 on LLM API calls per intent. In practice, this likely means learning from prior interactions is critical to making an affordable AI.
Mapping Intent Into Action
The pain of deploying and operating software was famously captured in a 2010 Meme at Google “I just want to serve 5 Tb”. The meme captured that simple objectives (e.g. serving some data) can turn into a bewildering complicated tree of operations due to system complexity and business requirements. The goal of Foyle is to solve this problem of translating intent into actions.
Since we are using Foyle to build Foyle, we can evaluate it by how well it learns to assist us with everyday tasks. The video below illustrates how we use Foyle to troubleshoot the AI we are building by fetching traces.
The diagram below illustrates how Foyle works.

In the video, we are using Foyle to fetch the trace for a specific prediction. This is a fundamental step in any AI Engineer’s workflow. The trace contains the information needed to understand the AI’s answer; e.g. the prompts to the LLMs, the result of post-processing etc… Foyle takes the markdown produced by ChatGPT and turns it into a set of blocks and assigns each block a unique ID. So to understand why a particular block was generated we might ask for the block trace as follows
show the block logs for block 01HZ3K97HMF590J823F10RJZ4T
The first time we ask Foyle to help us it has no prior interactions to learn from so it largely passes along the request to ChatGPT and we get the following response
blockchain-cli show-block-logs 01HZ3K97HMF590J823F10RJZ4T
Unsurprisingly, this is completely wrong because ChatGPT has no knowledge of Foyle; its just guessing. The first time we ask for a trace, we would fix the command to use Foyle’s REST endpoint to fetch the logs
curl http://localhost:8080/api/blocklogs/01HZ3K97HMF590J823F10RJZ4T | jq .
Since Foyle is instrumented to log user interactions it learns from this interaction. So the next time we ask for a trace e.g.
get the log for block 01HZ0N1ZZ8NJ7PSRYB6WEMH08M
Foyle responds with the correct answer
curl http://localhost:8080/api/blocklogs/01HZ0N1ZZ8NJ7PSRYB6WEMH08M | jq .
Notably, this example illustrates that Foyle is learning how to map higher level concepts (e.g. block logs) into low level concrete actions (e.g. curl).
Results
To measure Foyle’s ability to learn and assist with mapping intent into action, we created an evaluation dataset of 24 examples of intents specific to building and operating Foyle. The dataset consists of the following
- Evaluation Data: 24 pairs of (intent, action) where the action is a command that correctly achieves the intent
- Training Data: 27 pairs of (intent, action) representing user interactions logged by Foyle
- These were the result of our daily use of Foyle to build Foyle
To evaluate the effectiveness of human feedback we compared using GPT3.5 without examples to GPT3.5 with examples. Using examples, we prompt GPT3.5 with similar examples from prior usage(the prompt is here). Prior examples are selected by using similarity search to find the intents most similar to the current one. To measure the correctness of the generated commands we use a version of edit distance that measures the number of arguments that need to be changed. The binary itself counts as an argument. This metric can be normalized so that 0 means the predicted command is an exact match and 1 means the predicted command is completely different (precise details are here).
The Table 1. below shows that Foyle performs significantly better when using prior examples. The full results are in the appendix. Notably, in 15 of the examples where using ChatGPT without examples was wrong it was completely wrong. This isn’t at all surprising given GPT3.5 is missing critical information to answer these questions.
| Number of Examples | Percentage | |
| Performed Better With Examples | 19 | 79% |
| Did Better or Just As Good With Examples | 22 | 91% |
| Did Worse With Examples | 2 | 8% |
Table 1: Shows that for 19 of the examples (79%); the AI performed better when learning from prior examples. In 22 of the 24 examples (91%) using the prior examples the AI did no worse than baseline. In 2 cases, using prior examples decreased the AI’s performance. The full results are provided in the table below.
Distance Metric
Our distance metrics assumes there are specific tools that should be used to accomplish a task even when different solutions might produce identical answers. In the context of devops this is desirable because there is a cost to supporting a tool; e.g. ensuring it is available on all machines. As a result, platform teams are often opinionated about how things should be done.
For example to fetch the block logs for block 01HZ0N1ZZ8NJ7PSRYB6WEMH08M we measure the distance to the command
curl http://localhost:8080/api/blocklogs/01HZ0N1ZZ8NJ7PSRYB6WEMH08M | jq .
Using our metric if the AI answered
wget -q -O - http://localhost:8080/api/blocklogs/01HZ0N1ZZ8NJ7PSRYB6WEMH08M | yq .
The distance would end up being .625. The longest command consists of 8 arguments (including the binaries and the pipe operator). 3 deletions and 2 substitutions are needed to transform the actual into the expected answer which yields a distance of ⅝=.625. So in this case, we’d conclude the AI’s answer was largely wrong even though wget produces the exact same output as curl in this case. If an organization is standardizing on curl over wget then the evaluation metric is capturing that preference.
How much is good data worth?
A lot of agents appear to be pursuing a solution based on throwing lots of data and lots of compute at the problem. For example, to figure out how to “Get the log for block XYZ”, an agent could in principle crawl the Foyle and RunMe repositories to understand what a block is and that Foyle exposes a REST server to make them accessible. That approach might cost $2-$10 in LLM calls whereas with Foyle it’s less than $.002.
The Foyle repository is ~400K characters of Go Code; the RunMe Go code base is ~1.5M characters. So lets say 2M characters which is about 500K-1M tokens. With GPT-4-turbo that’s ~$2-$10; or about 1-7 SWE minutes (assuming $90 per hour). If the Agent needs to call GPT4 multiple times those costs are going to add up pretty quickly.
Where is Foyle Going
Today, Foyle is only learning single step workflows. While this is valuable, a lot of a toil involves multi step workflows. We’d like to extend Foyle to support this use case. This likely requires changes to how Foyle learns and how we evaluate Foyle.
Foyle only works if we log user interactions. This means we need to create a UX that is compelling enough for developers to want to use. Foyle is now integrated with Runme. We want to work with the Runme team to create features (e.g. Renderers, multiple executor support) that give users a reason to adopt a new tool even without AI.
How You Can Help
If you’re rethinking how you do playbooks and want to create AI assisted executable playbooks please get in touch via email jeremy@lewi.us or by starting a discussion in GitHub. In particular, if you’re struggling with observability and want to use AI to assist in query creation and create rich artifacts combining markdown, commands, and rich visualizations, we’d love to learn more about your use case.
Appendix: Full Results
The table below provides the prompts, RAG results, and distances for the entire evaluation dataset.
| prompt | best_rag | Baseline Normalized | Learned Distance |
| Get the ids of the execution traces for block 01HZ0W9X2XF914XMG6REX1WVWG | get the ids of the execution traces for block 01HZ3K97HMF590J823F10RJZ4T | 0.6666667 | 0 |
| Fetch the replicate API token | Show the replicate key | 1 | 0 |
| List the GCB jobs that build image backend/caribou | list the GCB builds for commit 48434d2 | 0.5714286 | 0.2857143 |
| Get the log for block 01HZ0N1ZZ8NJ7PSRYB6WEMH08M | show the blocklogs for block 01HZ3K97HMF590J823F10RJZ4T ... | 1 | 0 |
| How big is foyle's evaluation data set? | Print the size of foyle's evaluation dataset | 1 | 0 |
| List the most recent image builds | List the builds | 1 | 0.5714286 |
| Run foyle training | Run foyle training | 0.6666667 | 0.6 |
| Show any drift in the dev infrastructure | show a diff of the dev infra | 1 | 0.4 |
| List images | List the builds | 0.75 | 0.75 |
| Get the cloud build jobs for commit abc1234 | list the GCB builds for commit 48434d2 | 0.625 | 0.14285715 |
| Push the honeycomb nl to query model to replicate | Push the model honeycomb to the jlewi repository | 1 | 0.33333334 |
| Sync the dev infra | show a diff of the dev infra | 1 | 0.5833333 |
| Get the trace that generated block 01HZ0W9X2XF914XMG6REX1WVWG | get the ids of the execution traces for block 01HZ3K97HMF590J823F10RJZ4T | 1 | 0 |
| How many characters are in the foyle codebase? | Print the size of foyle's evaluation dataset | 1 | 0.875 |
| Add the tag 6f19eac45ccb88cc176776ea79411f834a12a575 to the image ghcr.io/jlewi/vscode-web-assets:v20240403t185418 | add the tag v0-2-0 to the image ghcr.io/vscode/someimage:v20240403t185418 | 0.5 | 0 |
| Get the logs for building the image carabou | List the builds | 1 | 0.875 |
| Create a PR description | show a diff of the dev infra | 1 | 1 |
| Describe the dev cluster? | show the dev cluster | 1 | 0 |
| Start foyle | Run foyle | 1 | 0 |
| Check for preemptible A100 quota in us-central1 | show a diff of the dev infra | 0.16666667 | 0.71428573 |
| Generate a honeycomb query to count the number of traces for the last 7 days broken down by region in the foyle dataset | Generate a honeycomb query to get number of errors per day for the last 28 days | 0.68421054 | 0.8235294 |
| Dump the istio routes for the pod jupyter in namespace kubeflow | list the istio ingress routes for the pod foo in namespace bar | 0.5 | 0 |
| Sync the manifests to the dev cluster | Use gitops to aply the latest manifests to the dev cluster | 1 | 0 |
| Check the runme logs for an execution for the block 01HYZXS2Q5XYX7P3PT1KH5Q881 | get the ids of the execution traces for block 01HZ3K97HMF590J823F10RJZ4T | 1 | 1 |
Table 2. The full results for the evaluation dataset. The left column shows the evaluation prompt. The second column shows the most similar prior example (only the query is shown). The third column is the normalized distance for the baseline AI. The 4th column is the normalized distance when learning from prior examples.
Without a copilot for devops we won't keep up
Since co-pilot launched in 2021, AI accelerated software development has become the norm. More importantly, as Simon Willison argued at last year’s AI Engineer Summit with AI there has never been an easier time to learn to code. This means the population of people writing code is set to explode. All of this begs the question, who is going to operate all this software? While writing code is getting easier, our infrastructure is becoming more complex and harder to understand. Perhaps we shouldn’t be surprised that as the cost of writing software decreases, we see an explosion in the number of tools and abstractions increasing complexity; the expanding CNCF landscape is a great illustration of this.
The only way to keep up with AI assisted coding is with AI assisted operations. While we are being flooded with copilots and autopilots for writing software, there has been much less progress with assistants for operations. This is because 1) everyone’s infrastructure is different; an outcome of the combinatorial complexity of today’s options and 2) there is no single system with a complete and up to date picture of a company’s infrastructure.
Consider a problem that has bedeviled me ever since I started working on Kubeflow; “I just want to deploy Jupyter on my company’s Cloud and access it securely.” To begin to ask AIs (ChatGPT, Claude, Bard) for help we need to teach them about our infrastructure; e.g. What do we use for compute, ECS, GKE, GCE? What are we using for VPN; tailscale, IAP, Cognito? How do we attach credentials to Jupyter so we can access internal data stores? What should we do for storage; Persistent disk or File store?
The fundamental problem is mapping a user’s intent, “deploy Jupyter”, to the specific set of operations to achieve that within our organization. The current solution is to build platforms that create higher level abstractions that hopefully more closely map to user intent while hiding implementation details. Unfortunately, building platforms is expensive and time consuming. I have talked to organizations with 100s of engineers building an internal developer platform (IDP).
Foyle is an OSS project that aims to simplify software operations with AI. Foyle uses notebooks to create a UX that encourages developers to express intent as well as actions. By logging this data, Foyle is able to build models that predict the operations needed to achieve a given intent. This is a problem which LLMs are unquestionably good at.
Demo
Let’s consider one of the most basic operations; fetching the logs to understand why something isn’t working. Observability is critical but at least for me a constant headache. Each observability tool has their own hard to remember query language and queries depend on how applications were instrumented. As an example, Hydros is a tool I built for CICD. To figure out whether hydros successfully built an image or hydrated some manifests I need to query its logs.
A convenient and easy way for me to express my intent is with the query
fetch the hydros logs for the image vscode-ext
If we send this to an AI (e.g. ChatGPT) with no knowledge of our infrastructure we get an answer which is completely wrong.
hydros logs vscode-ext
This is a good guess but wrong because my logs are stored in Google Cloud Logging. The correct query executed using gcloud is the following.
gcloud logging read 'logName="projects/foyle-dev/logs/hydros" jsonPayload.image="vscode-ext"' --freshness=1d --project=foyle-dev
Now the very first time I access hydros logs I’m going to have to help Foyle understand that I’m using Cloud Logging and how hydros structures its logs; i.e. that each log entry contains a field image with the name of the image being logged. However, since Foyle logs the intent and final action it is able to learn. The next time I need to access logs if I issue a query like
show the hydros logs for the image caribou
Foyle responds with the correct query
gcloud logging read 'logName="projects/foyle-dev/logs/hydros" jsonPayload.image="caribou"' --freshness=1d --project=foyle-dev
I have intentionally asked for an image that doesn’t exist because I wanted to test whether Foyle is able to learn the correct pattern as opposed to simply memorizing commands. Using a single example Foyle learns 1) what log is used by hydros and 2) how hydros uses structured logging to associate log messages with a particular image. This is possible because foundation models already have significant knowledge of relevant systems (i.e. gcloud and Cloud Logging).
Foyle relies on a UX which prioritizes collecting implicit feedback to teach the AI about our infrastructure.

In this interaction, a user asks an AI to translate their intent into one or more tools the user can invoke. The tools are rendered in executable, editable cells inside the notebook. This experience allows the user to iterate on the commands if necessary to arrive at the correct answer. Foyle logs these iterations (see this previous blog post for a detailed discussion) so it can learn from them.
The learning mechanism is quite simple. As denoted above we have the original query, Q, the initial answer from the AI, A, and then the final command, A’, the user executed. This gives us a triplet (Q, A, A’). If A=A’ the AI got the answer right; otherwise the AI made a mistake the user had to fix.
The AI can easily learn from its mistakes by storing the pairs (Q, A’). Given a new query Q* we can easily search for similar queries from the past where the AI made a mistake. Matching text based on semantic similarity is one of the problems LLMs excel at. Using LLMs we can compute the embedding of Q and Q* and measure the similarity to find similar queries from the past. Given a set of similar examples from the past {(Q1,A1’),(Q2,A2’),…,(Qn,An’)} we can use few shot prompting to get the LLM to learn from those past examples and answer the new query correctly. As demonstrated by the example above this works quite well.
This pattern of collecting implicit human feedback and learning from it is becoming increasingly common. Dosu uses this pattern to build AIs that can automatically label issues.
An IDE For DevOps
One of the biggest barriers to building copilots for devops is that when it comes to operating infrastructure we are constantly switching between different modalities
- We use IDEs/Editors to edit our IAC configs
- We use terminals to invoke CLIs
- We use UIs for click ops and visualization
- We use tickets/docs to capture intent and analysis
- We use proprietary web apps to get help from AIs
This fragmented experience for operations is a barrier to collecting data that would let us train powerful assistants. Compare this to writing software where a developer can use a single IDE to write, build, and test their software. When these systems are well instrumented you can train really valuable software assistants like Google’s DIDACT and Replit Code Repair.
This is an opportunity to create a better experience for devops even in the absence of AI. A great example of this is what the Runme.dev project is doing. Below is a screenshot of a Runme.dev interactive widget for VMs rendered directly in the notebook.

This illustrates a UX where users don’t need to choose between the convenience of ClickOps and being able to log intent and action. Another great example is Datadog Notebooks. When I was at Primer, I found using Datadog notebooks to troubleshoot and document issues was far superior to copying and pasting links and images into tickets or Google Docs.
Conclusion: Leading the AI Wave
If you’re a platform engineer like me you’ve probably spent previous waves of AI building tools to support AI builders; e.g. by exposing GPUs or deploying critical applications like Jupyter. Now we, platform engineers, are in a position to use AI to solve our own problems and better serve our customers. Despite all the excitement about AI, there’s a shortage of examples of AI positively transforming how we work. Let’s make platform engineering a success story for AI.
Acknowledgements
I really appreciate Hamel Husain reviewing and editing this post.
Logging Implicit Human Feedback
Foyle is an open source assistant to help software developers deal with the pain of devops. Developers are expected to operate their software which means dealing with the complexity of Cloud. Foyle aims to simplify operations with AI. One of Foyle’s central premises is that creating a UX that implicitly captures human feedback is critical to building AIs that effectively assist us with operations. This post describes how Foyle logs that feedback.
The Problem
As software developers, we all ask AIs (ChatGPT, Claude, Bard, Ollama, etc.…) to write commands to perform operations. These AIs often make mistakes. This is especially true when the correct answer depends on internal knowledge, which the AI doesn’t have.
- What region, cluster, or namespace is used for dev vs. prod?
- What resources is the internal code name “caribou” referring to?
- What logging schema is used by our internal CICD tool?
The experience today is
- Ask an assistant for one or more commands
- Copy those commands to a terminal
- Iterate on those commands until they are correct
When it comes to building better AIs, the human feedback provided by the last step is gold. Yet today’s UX doesn’t allow us to capture this feedback easily. At best, this feedback is often collected out of band as part of a data curation step. This is problematic for two reasons. First, it’s more expensive because it requires paying for labels (in time or money). Second, if we’re dealing with complex, bespoke internal systems, it can be hard to find people with the requisite expertise.
Frontend
If we want to collect human feedback, we need to create a single unified experience for
- Asking the AI for help
- Editing/Executing AI suggested operations
If users are copying and pasting between two different applications the likelihood of being able to instrument it to collect feedback goes way down. Fortunately, we already have a well-adopted and familiar pattern for combining exposition, commands/code, and rich output. Its notebooks.
Foyle’s frontend is VSCode notebooks. In Foyle, when you ask an AI for assistance, the output is rendered as cells in the notebook. The cells contain shell commands that can then be used to execute those commands either locally or remotely using the notebook controller API, which talks to a Foyle server. Here’s a short video illustrating the key interactions.
Crucially, cells are central to how Foyle creates a UX that automatically collects human feedback. When the AI generates a cell, it attaches a UUID to that cell. That UUID links the cell to a trace that captures all the processing the AI did to generate it (e.g any LLM calls, RAG calls, etc…). In VSCode, we can use cell metadata to track the UUID associated with a cell.
When a user executes a cell, the frontend sends the contents of the cell along with its UUID to the Foyle server. The UUID then links the cell to a trace of its execution. The cell’s UUID can be used to join the trace of how the AI generated the cell with a trace of what the user actually executed. By comparing the two we can easily see if the user made any corrections to what the AI suggested.

Traces
Capturing traces of the AI and execution are essential to logging human feedback. Foyle is designed to run on your infrastructure (whether locally or in your Cloud). Therefore, it’s critical that Foyle not be too opinionated about how traces are logged. Fortunately, this is a well-solved problem. The standard pattern is:
- Instrument the app using structured logs
- App emits logs to stdout and stderr
- When deploying the app collect stdout and stderr and ship them to whatever backend you want to use (e.g. Google Cloud Logging, Datadog, Splunk etc…)
When running locally, setting up an agent to collect logs can be annoying, so Foyle has the built-in ability to log to files. We are currently evaluating the need to add direct support for other backends like Cloud Logging. This should only matter when running locally because if you’re deploying on Cloud chances are your infrastructure is already instrumented to collect stdout and stderr and ship them to your backend of choice.
Don’t reinvent logging
Using existing logging libraries that support structured logging seems so obvious to me that it hardly seems worth mentioning. Except, within the AI Engineering/LLMOps community, it’s not clear to me that people are reusing existing libraries and patterns. Notably, I’m seeing a new class of observability solutions that require you to instrument your code with their SDK. I think this is undesirable as it violates the separation of concerns between how an application is instrumented and how that telemetry is stored, processed, and rendered. My current opinion is that Agent/LLM observability can often be achieved by reusing existing logging patterns. So, in defense of that view, here’s the solution I’ve opted for.
Structured logging means that each log line is a JSON record which can contain arbitrary fields. To Capture LLM or RAG requests and responses, I log them; e.g.
request := openai.ChatCompletionRequest{
Model: a.config.GetModel(),
Messages: messages,
MaxTokens: 2000,
Temperature: temperature,
}
log.Info("OpenAI:CreateChatCompletion", "request", request)
This ends up logging the request in JSON format. Here’s an example
{
"severity": "info",
"time": 1713818994.8880482,
"caller": "agent/agent.go:132",
"function": "github.com/jlewi/foyle/app/pkg/agent.(*Agent).completeWithRetries",
"message": "OpenAI:CreateChatCompletion response",
"traceId": "36eb348d00d373e40552600565fccd03",
"resp": {
"id": "chatcmpl-9GutlxUSClFaksqjtOg0StpGe9mqu",
"object": "chat.completion",
"created": 1713818993,
"model": "gpt-3.5-turbo-0125",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "To list all the images in Artifact Registry using `gcloud`, you can use the following command:\n\n```bash\ngcloud artifacts repositories list --location=LOCATION\n```\n\nReplace `LOCATION` with the location of your Artifact Registry. For example, if your Artifact Registry is in the `us-central1` location, you would run:\n\n```bash\ngcloud artifacts repositories list --location=us-central1\n```"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 329,
"completion_tokens": 84,
"total_tokens": 413
},
"system_fingerprint": "fp_c2295e73ad"
}
}
A single request can generate multiple log entries. To group all the log entries related to a particular request, I attach a trace id to each log message.
func (a *Agent) Generate(ctx context.Context, req *v1alpha1.GenerateRequest) (*v1alpha1.GenerateResponse, error) {
span := trace.SpanFromContext(ctx)
log := logs.FromContext(ctx)
log = log.WithValues("traceId", span.SpanContext().TraceID())
Since I’ve instrumented Foyle with open telemetry(OTEL), each request is automatically assigned a trace id. I attach that trace id to all the log entries associated with that request. Using the trace id assigned by OTEL means I can link the logs with the open telemetry trace data.
OTEL is an open standard for distributed tracing. I find OTEL great for instrumenting my code to understand how long different parts of my code took, how often errors occur and how many requests I’m getting. You can use OTEL for LLM Observability; here’s an example. However, I chose logs because as noted in the next section they are easier to mine.
Aside: Structured Logging In Python
Python’s logging module supports structured logging. In Python you can use the extra argument to pass an arbitrary dictionary of values. In python the equivalent would be:
logger.info("OpenAI:CreateChatCompletion", extra={'request': request, "traceId": traceId})
You then configure the logging module to use the python-json-logger formatter to emit logs as JSON. Here’s the logging.conf I use for Python.
Logs Need To Be Mined
Post-processing your logs is often critical to unlocking the most valuable insights. In the context of Foyle, I want a record for each cell that captures how it was generated and any subsequent executions of that cell. To produce this, I need to write a simple ETL pipeline that does the following:
- Build a trace by grouping log entries by trace ID
- Reykey each trace by the cell id the trace is associated with
- Group traces by cell id
This logic is highly specific to Foyle. No observability tool will support it out of box.
Consequently, a key consideration for my observability backend is how easily it can be wired up to my preferred ETL tool. Logs processing is such a common use case that most existing logging providers likely have good support for exporting your logs. With Google Cloud Logging for example it’s easy to setup log sinks to route logs to GCS, BigQuery or PubSub for additional processing.
Visualization
The final piece is being able to easily visualize the traces to inspect what’s going on. Arguably, this is where you might expect LLM/AI focused tools might shine. Unfortunately, as the previous section illustrates, the primary way I want to view Foyle’s data is to look at the processing associated with a particular cell. This requires post-processing the raw logs. As a result, out of box visualizations won’t let me view the data in the most meaningful way.
To solve the visualization problem, I’ve built a lightweight progressive web app(PWA) in Go (code) using maxence-charriere/go-app. While I won’t be winning any design awards, it allows me to get the job done quickly and reuse existing libraries. For example, to render markdown as HTML I could reuse the Go libraries I was already using (yuin/goldmark). More importantly, I don’t have to wrestle with a stack(typescript, REACT, etc…) that I’m not proficient in. With Google Logs Analytics, I can query the logs using SQL. This makes it very easy to join and process a trace in the web app. This makes it possible to view traces in real-time without having to build and deploy a streaming pipeline.
Try Foyle
Please consider following the getting started guide to try out an early version of Foyle and share your thoughts by email(jeremy@lewi.us) on GitHub(jlewi/foyle) or on twitter (@jeremylewi)!
About Me
I’m a Machine Learning platform engineer with over 15 years of experience. I create platforms that facilitate the rapid deployment of AI into production. I worked on Google’s Vertex AI where I created Kubeflow, one of the most popular OSS frameworks for ML.
I’m open to new consulting work and other forms of advisory. If you need help with your project, send me a brief email at jeremy@lewi.us.
Acknowledgements
I really appreciate Hamel Husain and Joseph Gleasure reviewing and editing this post.
7 - Tech Notes
Objective:
Describe how we want to use technical notes and establish guidelines on authoring technical notes (TNs) for consistency.
Why TechNotes?
We use TNs communicate key ideas, topics, practices, and decisions for the project. TNs provide a historical record with minimal burden on the authors or readers. We will use TNs in Foyle to document our team engineering practices and technical “stakes-in-the-ground” in a “bite-sized” manner. Use a TN instead of email to communicate important/durable decisions or practices. Follow this up with an email notification to the team when the document is published.
TNs are not meant to replace documents such as User Guides or Detailed Design documents. However, many aspects of such larger docs can be discussed and formalized using a TN to feed into the authoring of these larger docs.
Guidelines
- All TNs have a unique ID that TNxxx where xxx is a sequential number
- Keep TNs brief, clear and to the point.
- Primary author is listed as owner. Secondary authors are recognized as co-creators.
- Allow contributors to add themselves in the contributors section.
- TNs are considered immutable once they are published. They should be deprecated or superceded by new TNs. This provides a historical timeline and prevents guesswork on whether a TN is still relevant.
- Only mark a TN published when ready (and approved, if there is an approver).
- If a TN is deprecated mark it so. If there is a newer version that supersedes it, put the new doc in the front matter.
Happy Tech-Noting
7.1 - TN001 Logging
Objective
Design logging to support capturing human feedback.
TL;DR
One of the key goals of Foyle is to collect human feedback to improve the quality of the AI. The key interaction that we want to capture is as follows
- User asks the AI to generate one or more commands
- User edits those commands
- User executes those commands
In particular, we want to be able to link the commands that the AI generated to the commands that the user ultimately executes. We can do this as follows
- When the AI generates any blocks it attaches a unique block id to each block
- When the frontend makes a request to the backend, the request includes the block ids of the blocks
- The blockid can then be used as a join key to link what the AI produced with what a human ultimately executed
Implementation
Protos
We need to add a new field to the Block proto to store the block id.
message Block {
...
string block_id = 7;
}
As of right now, we don’t attach a block id to the BlockOutput proto because
- We don’t have an immediate need for it
- Since
BlockOutputis a child of aBlockit is already linked to an id
Backend
On the backend we can rely on structured logging to log the various steps (e.g. RAG) that go into producing a block. We can add log statements to link a block id to a traceId so that we can see how that block was generated.
Logging Backend
When it comes to a logging backend the simplest most universal solution is to write the structured logs as JSONL to a file. The downside of this approach is that this schema wouldn’t be efficient for querying. We could solve that by choosing a logging backend that supports indexing. For example, SQLite or Google Cloud Logging. I think it will be simpler to start by appending to a file. Even if we end up adding SQLite it might be advantageous to have a separate ETL pipeline that reads the JSONL and writes it to SQLite. This way each entry in the SQLite database could potentially be a trace rather than a log entry.
To support this we need to modify App.SetupLogging to log to the appropriate file.
I don’t think we need to worry about log rotation. I think we can just generate a new timestamped file each time Foyle starts. In cases where Foyle might be truly long running (e.g. deployed on K8s) we should probably just be logging to stodut/stderr and relying on existing mechanisms (e.g. Cloud Logging to ingest those logs).
Logging Delete Events
We might also want to log delete block events. If the user deletes an AI generated block that’s a pretty strong signal that the AI made a mistake; for example providing an overly verbose command. We could log these events by adding a VSCode handler for the delete event. We could then add an RPC to the backend to log these events. I’ll probably leave this for a future version.
Finding Mistakes
One of the key goals of logging is to find mistakes. In the case of Foyle, a mistake is where the AI generated block got edited by the human before being executed. We can create a simple batch job (possibly using Dataflow) to find these examples. The job could look like the following
- Filter the logs to find entries and emit tuples corresponding to AI generated block (block_id, trace_id, contentents) and executed blocks (block_id, trace_id, contents)
- Join the two streams on block_id
- Compare the contents of the two blocks if they aren’t the same then it was a mistake
References
7.2 - TN002 Learning from Human Feedback
Objective
Allow Foyle to learn from human feedback.
TL;DR
If a user corrects a command generated by the AI, we want to be able to use that feedback to improve the AI. The simplest way to do this is using few shot prompting. This tech note focuses on how we will collect and retrieve the examples to enrich the prompts. At a high level, the process will look like the following
- Process logs to identify examples where the human corrected the AI generated response
- Turn each mistake into one or more examples of a query and response
- Compute and store the embeddings of the query
- Use brute force to compute distance to all embeddings
This initial design prioritizes simplicity and flexibility over performance. For example, we may want to experiment with using AI to generate alternative versions of a query. For now, we avoid using a vector database to efficiently store and query a large corpus of documents. I think its premature to optimize for large corpi given users may not have large corpi.
Generate Documents
The first step of learning from human feedback is to generate examples that can be used to train the AI. We can
think of each example as a tuple (Doc, Blocks) where Doc is the document sent to the AI for completion and
Blocks are the Blocks the AI should return.
We can obtain these examples from our block logs. A good starting point is to look
at where the AI made a mistake; i.e. the human had to edit the command the AI provided. We can obtain these
examples by looking at our BlockLogs and finding logs where the executed cell differed from the generated block.
There’s lots of ways we could store tuples (Doc, Blocks) but the simplest most obvious way is to append the desired
block to Doc.blocks and then serialize the Doc proto as a .foyle file. We can start by assuming that the query
corresponds to all but the last block Doc.blocks[:-1] and the expected answer is the last block Doc.Blocks[-1].
This will break when we want to allow for the AI to respond with more than 1 block. However, to get started this
should be good enough. Since the embeddings will be stored in an auxilary file containing a serialized proto we
could extend that to include information about which blocks to use as the answer.
Embeddings
In Memory + Brute Force
With text-embedding-3-small embeddings have dimension 1536 and are float32; so 6KB/Embedding. If we have 1000 documents that’s 6MB. This should easily fit in memory for the near future.
Computation wise computing a dot product against 1000 documents is about 3.1 Million Floating Point Operations(FLOPS). This is orders of magnitude less than LLAMA2 which clocks in at 1700 Giga Flops. Given people are running LLAMA2 locally (albeit on GPUs) seems like we should be able to get pretty far with a brute force approach.
A brute force in memory option would work as follows
- Load all the vector embeddings of documents into memory
- Compute a dot product using matrix multiplication
- Find the K-values with the smallest values
Serializing the embeddings.
To store the embeddings we will use a serialized proto that lives side by side with the file we computed the embeddings
for. As proposed in the previous section we will store the example in the file ${BLOCKLOG}.foyle then its embeddings will live in the file
“${BLOCKLOG}.binpb”. This will contain a serialized proto like the following
message Example {
repeated float32 embedding;
}
We use a proto so that we can potentially enrich the data format over time. For example, we may want to
- Store a hash of the source text so we can determine when to recompute embeddings
- Store additional metadata
- Store multiple embeddings for the same document corresponding to different segmentations
This design makes it easy to add/remove documents from the collection we can
- Add “.foyle” or “.md” documents
- Use globs to match files
- Check if the embeddings already exist
The downside of this approach is likely performance. Opening and deserializing large numbers of files is almost certainly going to be less efficient then using a format like hdf5 that is optimized for matrices.
Learn command
We can add a command to the Foyle CLI to perform all these steps.
foyle learn
This command will operate in a level based, declarative way. Each time it is invoked it will determine what work needs to be done and then perform it. If no additional work is needed it will be a null op. This design means we can run it periodically as a background process so that learning happens automatically.
Here’s how it will work; it will iterate over the log entries in the block logs to identify logs that need to
be processed. We can use a watermark to keep track of processed logs to avoid constantly rereading the entire log
history. For each BlockLog that should be turned into an example we can look for the file {BLOCK_ID}.foyle;
if the file doesn’t exist then we will create it.
Next, we can check that for each {BLOCK_ID}.foyle file there is a corresponding {BLOCK_ID}.embeddings.binpb
file. If it doesn’t exist then we will compute the embeddings.
Discussion
Why Only Mistakes
In the current proposal we only turn mistakes into examples. In principle, we could use examples where the model got things right as well. The intuition is that if the model is already correctly handling a query; there’s no reason to include few shot examples. Arguably, those positive examples might end up confusing the AI if we end up retrieving them rather than examples corresponding to mistakes.
Why duplicate the documents?
The ${BLOCK_ID}.foyle files are likely very similar to the actual .foyle files the user created. An alternative
design would be to just reuse the original .foyle documents. This is problematic for several reasons.
The {BLOCK_ID}.foyle files are best considered internal to Foyle’s self-learning and shouldn’t be directly under
the user’s control. Under the current proposal the {BLOCK_ID}.foyle are generated from logs and represent snapshots
of the user’s documents at specific points in time. If we used the user’s actual files we’d have to worry about
them changing over time and causing problems. Treating them as internal to Foyle also makes it easier to move them
in the future to a different storage backend. It also doesn’t require Foyle to have access to the user’s storage system.
Use a vector DB
Another option would be to use a vector DB. Using a vector database (e.g. Weaviate, Chroma, Pinecone) adds a lot of complexity. In particular, it creates an additional dependency which could be a barrier for users just interested in trying Foyle out. Furthermore, a vector DB means we need to think about schemas, indexes, updates, etc… Until its clear we have sufficient data to benefit from a vector db its not worth introducing.
References
OpenAI Embeddings Are Normalized
- Reference doc explaining that OpenAI embeddings are normalized to length 1. Weaviate Schemas Common File Extensions For Protos
7.3 - TN003 Learning Evaluation
Objective
Measure the efficacy of the learning system.
TL;DR
The key hypothesis of Foyle is that by using implicit human feedback, we can create an AI that automatically learns about your infrastructure. In TN002_Learning and PR#83 we implemented a very simple learning mechanism based on query dependent few shot prompting. The next step is to quantiatively evaluate the effectiveness of this system. We’d like to construct an evaluation data set that consists of queries whose answers depend on private knowledge of your infrastructure. We’d like to compare the performance of Foyle before and after learning from human feedback. We propose to achieve this as follows
Manually construct an evaluation dataset consisting of queries whose answers depend on private knowledge of your infrastructure ${(q_0, r_0), …. (q_n, r_n)}$.
For each query $q_i$ in the evaluation dataset, we will generate a command $r’_i$ using the Agent.
Compute an evaluation score using a metric similar to the edit distance
$$ S = \sum_{i=0}^n D(r_i, r’_i) $$
Compare the scores before and after learning from human feedback.
Learning: What Do We Want To Learn
In the context of DevOps there are different types of learning we can test for. The simplest things are facts. These are discrete pieces of information that can’t be derived from other information. For example:
Query: “Which cluster is used for development?
Response: “gcloud container clusters describe –region=us-west1 –project=foyle-dev dev”
The fact that your organization is using a GKE cluster in the us-west1 region in project foyle-dev for development (and not an EKS cluster in us-west1) is something a teammate needs to tell you. In the context of our Agent, what we want the agent to learn is alternative ways to ask the same question. For example, “Show me the cluster where dev workloads run” should return the same response.
As a team’s infrastructure grows, they often develop conventions for doing things in a consistent way. A simple
example of this is naming conventions. For example, as the number of docker images grows, most organizations develop
conventions around image tagging; e.g. using live or prod to indicate the production version of an image.
In the context of Foyle, we’d like to evaluate the efficacy with which Foyle learns these conventions from examples.
For example, our training set might include the example
Query: “Show me the latest version of the production image for hydros”
Response: “gcloud artifacts docker images describe us-west1-docker.pkg.dev/foyle-public/images/hydros/hydros:prod”
Our evaluation set might include the example
Query: “Describe the production image for foyle”
Response: “gcloud artifacts docker images describe us-west1-docker.pkg.dev/foyle-public/images/foyle/foyle:prod”
Notably, unlike the previous example, in this case both the query and response are different. In order for the agent to generalize to images not in the training set, it needs to learn the convention that we use to tag images.
Multi-step
We’d eventually like to be able to support multi-step queries. For example, a user might ask “Show me the logs for the most recent image build for foyle”. This requires two steps
- Listing the images to find the sha of the most recent image
- Querying for the logs of the image build with that sha
We leave this for future work.
Building an Evaluation Set
We will start by hand crafting our evaluation set.
Our evaluation set will consist of a set of .foyle documents checked into source control in the data
directory. The evaluation data set is specific to an organization and its infrastructure. We will use the infrastructure
of Foyle’s development team as the basis for our evaluation set.
To test Foyle’s ability to learn conventions we will include examples that exercise conventions for non-existent infrastructure (e.g. images, deployments, etc…). Since they don’t exist, a user wouldn’t actually query for them so they shouldn’t appear in our logs.
We can automatically classify each examples in the evaluation set as either a memorization or generalization example based on whether the response matches one of the responses in the training set. We can use the distance metric proposed below to measure the similarity between the generated command and the actual command.
Evaluating correctness
We can evaluate the correctness of the Agent by comparing the generated commands with the actual commands. We can use an error metric similar to edit distance. Rather than comparing individual characters, we will compare arguments as a whole. First we will divide a command into positional and named arguments. For this purpose the command itself is the first positional argument. For the positional we compute the edit distance but looking at the entirety of the positional argument. For the named arguments we match arguments by name and count the number of incorrect, missing, and extra arguments. We can denote this as follows. Let $a$ and $b$ be the sequence of positionsal arguments for two different commands $r_a$ and $r_b$ that we wish to compare.
$$ a = {a_0, …, a_{m}} $$
$$ b = {b_0, …, b_{n}} $$
Then we can define the edit distance between the positional arguments as
$$ distance = D_p(m,n) $$
$$ D_p(i,0) = \sum_{k=0}^{i} w_{del}(a_k) $$
$$ D_p(0,j) = \sum_{k=0}^{j} w_{ins}(b_k) $$
$$ D_p(i, j) = \begin{cases} D_p(i-1, j-1) & \text{if } a_i = b_j \ min \begin{cases} D_p(i-1, j) + w_{del}(a_i) \ D_p(i, j-1) + w_{ins}(b_j) \ D_p(i-1, j-1) + w_{sub}(a_i, b_j) \ \end{cases} & \text{if } a[i] \neq b[j] \end{cases} $$
Here $w_{del}$, $w_{ins}$, and $w_{sub}$ are weights for deletion, insertion, and substitution respectively. If $w_{del} = w_{ins}$ then the distance is symetric $D(r_a, r_b) = D(r_b, r_a)$.
We can treat named arguments as two dictionaries c and d. We can define the edit distance between the named arguments as follows
$$ K = \text{keys}(c) \cup \text{keys}(d) $$
$$ D_n = \sum_{k \in K} f(k) $$
$$ f(k) = \begin{cases} w_{del}(c[k]) & \text{if } k \notin \text{keys}(d) \ w_{ins}(d[k]) & \text{if } k \notin \text{keys}(c) \ w_{sub}(c[k], d[k]) & \text{if } k \in \text{keys}(c), k \in \text{keys}(d), c[k] \neq d[k] \ 0 & \text{otherwise} \ \end{cases} $$
This definition doesn’t properly account for the fact that named arguments often have a long and short version. We ignore this for now and accept that if one command uses the long version and the other uses the short version, we will count these as errors. In the future, we could try building a dictionary of known commands and normalizing the arguments to a standard form.
This definition also doesn’t account for the fact that many CLIs have subcommands and certain named arguments must appear before or after certain subcommands. The definition above would treat a named argument as a match as long it appears anywhere in the command.
The total distance between two commands is then
$$ D = D_p + D_n $$
Guardrails to avoid data leakage
We want to ensure that the evaluation set doesn’t contain any queries that are in the training set. There are two cases we need to consider
- Memorization: Queries are different but command is the same
- These are valid training, evaluation pairs because we expect the command to exactly match even though the queries are different
- Contamination: Queries are the same and commands are the same
We can use the distance metric proposed in the previous section to determine if a command in our training set matches the command in the eval dataset.
We can also use this to automatically classifiy each evaluation example as a memorization or generalization example. If the distance from the command in the evaluation set to the closest command in the training set is less than some threshold, we can classify it as a memorization example. Otherwise we can classify it as a generalization example.
Add an Option to filter out eval
When processing an evaluation dataset we should probably denote in the logs that the request was part of the evaluation set. This way during the learning process we can filter it out to avoid learning our evaluation dataset.
An easy way to do this would be to include a log field eval that is set to true for all evaluation examples. When constructing the logger in Agent.Generate we can set this field to true if the Agent is in eval mode.
We still want the Agent to log the evaluation examples so we can use the logs and traces to evaluate the Agent.
In the future we could potentially set the eval field in the request if we want to use the same server for both training and evaluation. For now, we’d probably run the Agent as a batch job and not start a server.
Alternatives
LLM Evaluation
Using an LLM to evaluate the correctness of generated responses is another option. I’m not sure what advantage this would offer over the proposed metric. The proposed metric has the advantage that it is interpratable and deteriminstic. LLM scoring would introduce another dimension of complexity; in particular we’d potentially need to calibrarte the LLM to align its scores with human scoring.
7.4 - TN004 Integration with Runme.Dev
Objective
Understand what it would take to integrate Foyle’s AI capabilities with runme.dev.
TL;DR
runme.dev is an OSS tool for running markdown workflows. At a high level its architecture is very similar to Foyle’s. It has a frontend based on vscode notebooks which talks to a GoLang server. It has several critical features that Foyle lacks:
- it supports native renderers which allow for output to be rendered as rich, interactive widgets in the notebook (examples)
- it supports streaming the output of commands
- it supports setting environment variables
- it supports redirecting stdout and stderr to files
- markdown is Runme’s native file format
- cell ids are persisted to markdown enabling lineage tracking when serializing to markdown
In short it is a mature and feature complete tool for running Notebooks. Foyle, in contrast, is a bare bones prototype that has frustrating bugs (e.g. output isn’t scrollable). The intent of Foyle was always to focus on the AI capabilities. The whole point of using VSCode Notebooks was to leverage an existing OSS stack rather than building a new one. There’s no reason to build a separate stack if there’s is an OSS stack that meets our needs.
Furthermore, it looks like the RunMe community has significantly more expertise in building VSCode Extensions (vscode-awesome-ux and tangle). This could be a huge boon because it could open the door to exploring better affordances for interacting with the AI. The current UX in Foyle was designed entirely on minimizing the amount of frontend code.
Runme already has an existing community and users; its always easier to ship features to users than users to features.
For these reasons, integrating Foyle’s AI capabilities with Runme.dev is worth pursuing. Towards that end, this document tries to identify the work needed for a POC of integrating Foyle’s AI capabilities with Runme.dev. Building a POC seems like it would be relatively straightforward
- Foyle needs to add a new RPC to generate cells using Runme’s protos
- Runme’s vscode extension needs to support calling Foyle’s GenerateService and inserting the cells
Fortunately, since Runme is already assigning and tracking cell ids, very little needs to change to support collecting the implicit feedback that Foyle relies on.
The current proposal is designed to minimize the number of changes to either code base. In particular, the current proposal assumes Foyle would be started as a separate service and Runme would be configurable to call Foyle’s GenerateService. This should be good enough for experimentation. Since Foyle and Runme are both GoLang gRPC services, building a single binary is highly feasible but might require come refactoring.
Background
Execution in Runme.Dev
runme.dev uses the RunnerService to execute programs in a kernel. Kernels are stateful. Using the RunnerService the client can create sessions which persist state across program executions. The Execute method can then be used to execute a program inside a session or create a new session if none is specified.
IDs in Runme.Dev
Runme assigns ULIDs to cells. These get encoded in the language annotation of the fenced block when serializing to markdown.

These ids are automatically passed along in the known_id field of the ExecuteRequest.
In the Cell Proto. The id is stored in the metadata field id. When cells are persisted any information in the metadata will be stored in the language annotation of the fenced code block as illustrated above.
Logging in Runme.Dev
Runme uses Zap for logging. This is the same logger that Foyle uses.
Foyle Architecture
Foyle can be broken down into two main components
- GRPC Services that are a backend for the VSCode extension - these services are directly in the user request path
- Asynchronous learning - This is a set of asynchronous batch jobs that can be run to improve the AI. At a high level these jobs are responsible for extracting examples from the logs and then training the AI on those examples.
Foyle has two GRPC services called by the VSCode extension
- GenerateService - Uses AI to author cells to be inserted into the doc
- ExecuteService - Executes cells
For the purpose of integrating with Runme.dev only GenerateService matters because we’d be relying on Runme.dev to execute cells.
Integrating Foyle with Runme.Dev
Foyle Generate Service Changes
Foyle would need to expose a new RPC to generate cells using Runme’s protos.
message RunmeGenerateRequest {
runme.parser.v1.Notebook notebook;
}
message RunmeGenerateResponse {
repeated runme.parser.v1.Cell cells = 1;
}
service RunmeGenerateService {
rpc Generate (RunmeGenerateRequest) returns (RunmeGenerateResponse) {}
}
To implement this RPC we can just convert Runme’s protos to Foyle’s protos and then reuse the existing implementation.
Since Runme is using ULIDs Foyle could generate a ULID for each cell. It could then log the ULID along with the block id so we can link ULIDs to cell ids. In principle, we could refactor Foyle to use ULIDs instead of UUIDs.
Ideally, we’d reuse Runme’s ULID Generator to ensure consistency. That would require a bit of refactoring in Runme to make it accessible because it is currently private.
Runme Frontend Changes
Runme.dev would need to update its VSCode extension to call the new RunmeGenerateService and insert the cells.
This mostly likely entails adding a VSCode Command and hot key that the user can use to trigger the generation of cells.
Runme would presumably also want to add some configuration options to enable the Foyle plugin and configure the endpoint.
Runme Logging Changes
Foyle relies on structured logging to track cell execution. Runme uses Zap for logging and uses structured logging by default (code). This is probably good enough for a V0 but there might be some changes we want to make in the future. Since the AI’s ability to improve depends on structured logging to a file; we might want to configure two separate loggers so a user’s configuration doesn’t interfere with the AI’s ability to learn. Foyle uses a Zap Tee Core to route logs to multiple sinks. Runme could potentially adopt the same approach if its needed.
I suspect Runme’s execution code is already instrumented to log the information we need but if not we may need to add some logging statements.
Changes to Foyle Learning
We’d need to update Foyle’s learning logic to properly extract execution information from Runme’s logs.
Security & CORS
Foyle already supports CORs. So users can already configure CORS in Foyle to accept requests from Runme.dev if its running in the browser.
Discussion
There are two big differences between how Foyle and Runme work today
- Runme’s Kernel is stateful where as Foyle’s Kernel is stateless
- There is currently no concept of a session in Foyle
- Foyle currently runs vscode entirely in the web; Runme can run vscode in the web but depends on code-server
One potential use case where this comes up is if you want to centrally manage Foyle for an organization. I heard from one customer that they wanted a centrally deployed webapp so that users didn’t have to install anything locally. If the frontend is a progressive web app and the kernel is stateless then its easy, cheap, and highly scalable to deploy this centrally. I’d be curious if this is a deployment configuration that Runme has heard customers asking for?
References
Runme.dev source links
- Parser Service
- Handles serialization to/from markdown to a notebook
- Runner Service
- Responsible for actually executing commands
- Implementation of the runner service
- The repository containing the vscode extension for runme.dev kernel.ts VSCodeNotebook Controller
- _doExecuteCell execute an individual cell
- _executeAll
Appendix: Miscellaneous notes about how runme.dev works
If an execute request doesn’t have a session id, a new session is created code
It uses a pseudo terminal to execute commands code
It looks like the VSCode extension relies on the backend doing serialization via RPC code however it looks like they are experimenting with possibly using WASM to make it run in the client
- It manages a map from cells to a NotebookCellOutputManager
- It contains a VSCodeNotebookController
- I think NotebookCellOutputManager orchestrates executing a cell and rendering the outputs
- createNotebookCellExecution
- Launches a cell execution
7.5 - TN005 Continuous Log Processing
Objective
Continuously compute traces and block logs
TL;DR
Right now the user has to explicitly run
foyle log analyze- to compute the aggregated traces and block logsfoyle learn- to learn from the aggregated traces and block logs
This has a number of drawbacks that we’d like to fix jlewi/foyle#84
- Traces aren’t immediately available for debugging and troubleshooting
- User doesn’t immediately and automatically benefit from fixed examples
- Server needs to be stopped to analyze logs and learn because pebble can only be used from a single process jlewi/foyle#126
We’d like to fix this so that logs are continuously processed and learned from as a background process in the Foyle application. This technote focuses on the first piece which is continuous log processing.
Background
Foyle Logs
Each time the Foyle server starts it creates a new timestamped log file. Currently, we only expect one Foyle server to be running at a time. Thus, at any given time only the latest log file might still be open for additional writes.
RunMe Logs
RunMe launches multiple instances of the RunMe gRPC server. I think its one per vscode workspace. Each of these instances writes logs to a separate timestamped file. Currently, we don’t have a good mechanism to detect when a log file has been closed and will recieve no more writes.
Block Logs
Computing the block logs requires doing two joins
- We first need to join all the log entries by their trace ID
- We then need to key each trace by the block IDs associated with that
- We need to join all the traces related to a block id
File Backed Queue Based Implementations
rstudio/filequeue implements a FIFO using a file per item and relies on a timestamp in the filename to maintain ordering. It renames files to pop them from the queue.
nsqio/go-diskqueue uses numbered files to implement a FIFO queue. A metadata file is used to track the position for reading and writing. The library automatically rolls files when they reach a max size. Writes are asynchronous. Filesystem syncs happen periodically or whenever a certain number of items have been read or written. If we set the sync count to be one it will sync after every write.
Proposal
Accumulating Log Entries
We can accumulate log entries keyed by their trace ID in our KV store; for the existing local implementation this will be PebbleDB. In response to a new log entry we can fire an event to trigger a reduce operation on the log entries for that trace ID. This can in turn trigger a reduce operation on the block logs.
We need to track a watermark for each file so we know what entries have been processed. We can use the following data structure
// Map from a file to its watermark
type Watermarks map[string]Watermark
type Watermark struct {
// The offset in the file to continue reading from.
Offset int64
}
If a file is longer than the offset then there’s additional data to be processed. We can use fsnotify to get notified when a file has changed.
We could thus handle this as follows
- Create a FIFO where every event represents a file to be processed
- On startup register a fsnotifier for the directories containing logs
- Fire a sync event for each file when it is modified
- Enqueue an event for each file in the directories
- When processing each file read its watermark to determine where to read from
- Periodically persist the watermarks to disk and persist on shutdownTo make this work need to implement a queue with a watermark.
An in memory FIFO is fine because the durability comes from persisting the watermarks. If the watermarks are lost we would reprocess some log entries but that is fine. We can reuse Kubernetes WorkQueue to get “stinginess”; i.e avoid processing a given file multiple times concurrently and ensuring we only process a given item once if it is enqued multiple times before it can be processed.
The end of a given trace is marked by specific known log entries e.g. “returning response” so we can trigger accumulating a trace when those entries are seen.
The advantage of this approach is we can avoid needing to create another durable, queue to trigger trace processing because we can just rely on the watermark for the underlying log entry. In effect, those watermarks will track the completion of updating the traces associated with any log entries up to the watermark.
We could also use this trace ending messages to trigger garbage collection of the raw log entries in our KV store.
Implementation Details
Responsibility for opening up the pebble databases should move into our application class
- This will allow db references to be passed to any classes that need them
We should define a new DB to store the raw log entries
- We should define a new proto to represent the values
Analyzer should be changed to continuously process the log files
- Create a FIFO for log file events
- Persist watermarks to disk
- Register a fsnotifier for the directories containing logs
BlockLogs
When we perform a reduce operation on the log entries for a trace we can emit an event for any block logs that need to be updated. We can enqueue these in a durable queue using nsqio/go-diskqueue.
We need to accumulate (block -> traceIds[]string). We need to avoid multiple writers trying to update the same block concurrently because that would lead to a last one wins situation.
One option would be to have a single writer for the blocks database. Then we could just use a queue for different block updates. Downside here is we would be limited to a single thread processing all block updates.
An improved version of the above would be to have multiple writers but ensure a given block can only be processed by one worker at a time. We can use something like workqueue for this. Workqueue alone won’t be sufficient because it doesn’t let you attach a payload to the enqueued item. The enqueued item is used as the key. Therefore we’d need a separate mechanism to keep track of all the updates that need to be applied to the block.
An obvious place to accumulate updates to each block would be in the blocks database itself. Of course that brings us back to the problem of ensuring only a single writer to a given block at a time. We’d like to make it easy to for code to supply a function that will apply an update to a record in the database.
func ReadModifyWrite[T proto.Message](db *pebble.DB, key string, msg T, modify func(T) error) error {
...
}
To make this thread safe we need to ensure that we never try to update the same block concurrently. We can do that by implementing row level locks. fishy/rowlock is an example. It is basically, a locked map of row keys to locks. Unfortunately, it doesn’t implement any type of forgetting so we’d keep accumulating keys. I think we can use the builtin sync.Map to implement RowLocking with optimistic concurrency. The semantics would be like the following
- Add a ResourceVersion to the proto that can be used for optimistic locking
- Read the row from the database
- Set ResourceVersion if not already set
- Call LoadOrStore to load or store the resource version in the sync.Map
- If a different value is already stored then restart the operation
- Apply the update
- Generate a new resource version
- Call CompareAndSwap to update the resource version in the sync.Map
- If the value has changed then restart the operation
- Write the updated row to the database
- Call CompareAndDelete to remove the resource version from the sync.Map
Continuous Learning
When it comes to continuous learning we have to potential options
- We could compute any examples for learning as part of processing a blocklog
- We could have a separate queue for learning and add events as a result of processing a blocklog
I think it makes sense to keep learning as a separate step. The learning process will likely evolve over time and its advantageous if we can redo learning without having to reprocess the logs.
The details will be discussed in a subsequent tech note.
7.6 - TN006 Continuous Learning
Objective
- Continuously learn from the traces and block logs
TL;DR
TN005 Continuous Log Processing described how we can continuously process logs. This technote describes how we can continuously learn from the logs.
Background
How Learning Works
TN002 Learning provided the initial design for learning from human feedback.
This was implemented in Learner.Reconcile as two reconcilers
reconcile.reconcileExamples- Iterates over the blocks database and for each block produces a training example if one is requiredreconcile.reconcileEmbeddings- Iterates over the examples and produces embeddings for each example
Each block currently produces at most 1 training example and the block id and the example ID are the same.
InMemoryDB implements RAG using an in memory database.
Proposal
We can change the signature of Learner.Reconcile to be
func (l *Learner) Reconcile(ctx context.Context, id string) error
where id is a unique identifier for the block. We can also update Learner to use a workqueue to process blocks asynchronously.
func (l *Learner) Start(ctx context.Context, events <-chan string, updates chan<-string) error
The learner will listen for events on the event channel and when it receives an event it will enqueue the example
for reconciliation. The updates channel will be used to notify InMemoryDB that it needs to load/reload an example.
For actual implementation we can simplify Learning.reconcileExamples and Learning.reconcileEmbeddings
since we can eliminate the need to iterate over the entire database.
Connecting to the Analyzer
The analyzer needs to emit events when there is a block to be added. We can change the signature of the run function to be
func (a *Analyzer) Run(ctx context.Context, notifier func(string)error ) error
The notifier function will be called whenever there is a block to be added. Using a function means the Analyzer doesn’t have to worry about the underlying implementation (e.g. channel, workqueue, etc.).
Backfilling
We can support backfilling by adding a Backfill method to Learner which will iterate over the blocks database.
This is useful if we need to reprocess some blocks because of a bug or because of an error.
func (l *Learner) Backfill(ctx context.Context, startTime time.time) error
We can use startTime to filter down the blocks that get reprocessed. Only those blocks that were modified
after start time will get reprocessed.
InMemoryDB
We’d like to update InMemoryDB whenever an example is added or updated. We can use the updates channel
to notify InMemoryDB that it needs to load/reload an example.
Internally InMemoryDB uses a matrix and an array to store the data
- embeddings stores the embeddings for the examples in a num_examples x num_features.
- embeddings[i, :] is the embedding for examples[i]
We’ll need to add a map from example ID to the row in the embeddings matrix map[string]int. We’ll also
need to protect the data with a mutex to make it thread safe.
7.7 - TN007 Shared Learning
Objective
- Design a solution for sharing learning between multiple users
TL;DR
The examples used for in context learning are currently stored locally. This makes it awkward to share a trained AI between team members. Users would have to manually swap the examples in order to benefit from each others learnings. There are a couple key design decisions
- Do we centralize traces and block log events or only the learned examples?
- Do we support loading examples from a single location or multiple locations?
To simplify management I think we should do the following
- Only move the learned examples to a central location
- Trace/block logs should still be stored locally for each user
- Add support for loading/saving shared examples to multiple locations
Traces and block log events are currently stored in Pebble. Pebble doesn’t have a good story for using shared storage cockroachdb/pebble#3177. We also don’t have an immediate need to move the traces and block logs to a central location.
Treating shared storage location as a backup location means Foyle can still operate fine if the shared storage location is inaccessible.
Proposal
Users should be able to specify
- Multiple additional locations to load examples from
- A backup location to save learned examples to
LearnerConfig Changes
We can update LearnerConfig to support these changes
type LearnerConfig struct {
// SharedExamples is a list of locations to load examples from
SharedExamples []string `json:"sharedExamples,omitempty"`
// BackupExamples is the location to save learned examples to
BackupExamples string `json:"backupExamples,omitempty"`
}
Loading SharedExamples
To support different storage systems (e.g. S3, GCS, local file system) we can define an interface for working with shared examples. We currently have the FileHelper interface
type FileHelper interface {
Exists(path string) (bool, error)
NewReader(path string) (io.Reader, error)
NewWriter(path string) (io.Writer, error)
}
Our current implementation of inMemoryDB requires a Glob function to find all the examples that should be loaded. We should a new interface to include the Glob.
type Globber interface {
Glob(pattern string) ([]string, error)
}
For object storage we can implement Glob by listing all the objects matching a prefix and then applying the glob; similar to this code for matching a regex
Triggering Loading of SharedExamples
For an initial implementation we can load shared examples when Foyle starts and perhaps periodically poll for new examples. I don’t think there’s any need to implement push based notifications for new examples.
Alternatives
Centralize Traces and Block Logs
Since Pebble doesn’t have a good story for using shared storage cockroachdb/pebble#3177 there’s no simple solution for moving the traces and block logs to a central location.
The main thing we lose by not centralizing the traces and block is the ability to do bulk analysis of traces and block events across all users. Since we don’t have an immediate use case for that there’s no reason to support it.
References
7.8 - TN008 Auto Insert Cells
Objective
- Design to have Foyle automatically and continuously generate suggested cells to insert after the current cell as the user edits a cell in a notebook.
TL;DR
Today Foyle generates a completion when the user explicitly asks for a suggestion by invoking the generate completion command. The completion results in new cells which are then inserted after the current cell. We’d like to extend Foyle to automatically and continuously generate suggestions as the user edits a cell in a notebook. As a user edits the current cell, Foyle will generate one or more suggested cells to insert after the current cell. This cells will be rendered in a manner that makes it clear they are suggestions that haven’t been accepted or rejected yet. When the user finishes editing the current cell the suggested cells will be accepted or rejected.
This feature is very similar to how GitHub Copilot AutoComplete works. The key difference is that we won’t try to autocomplete the current cell.
Not requiring users to explicitly ask for a suggestion should improve the Foyle UX. Right now users have to enter the intent and then wait while Foyle generates a completion. This interrupts the flow state and requires users to explicitly think about asking for help. By auto-inserting suggestions we can mask that latency by generating suggestions as soon as a user starts typing and updating those suggestions as the expand the intent. This should also create a feedback loop which nudges users to improve the expressiveness of their intents to better steer Foyle.
Since Foyle learns by collecting feedback on completions, auto-generating suggestions increases the opportunity for learning and should allow Foyle to get smarter faster.
The UX should also be a bigstep towards assisting with intents that require multiple steps to achieve including ones where later steps are conditional on the output of earlier steps. One way achieve multi-step workflows is to recursively predict the next action given the original intent and all previous actions and their output. By auto-inserting cells we create a seamless UX for recursively generating next action predictions; all a user has to do is accept the suggestion and then execute the code cells; as soon as they do the next action will be automatically generated.
Motivation: Examples of Multi-Step Workflows
Here are some examples of multi-step workflows.
GitOps Workflows
Suppose we are using GitOps and Flux and want to determine whether the Foo service is up to
date. We can do this as follows. First we can use git to get latest commit of the repository
git ls-remote https://github.com/acme/foo.git
Next we can get the flux kustomization for the Foo service to see what git commit has been applied
kubectl get kustomization foo -o jsonpath='{.status.lastAppliedRevision}'
Finally we can compare the two commits to see if the service is up to date.
Notably, in this example neither of the commands directly depends on the output of another command. However, this won’t always be the case. For example, if we wanted to check whether a particular K8s deployment was up to date we might do the following
- Use
kubectl get deployto get the flux annotationkustomize.toolkit.fluxcd.io/nameto identify the kustomization - Use
kubectl get kustomizationto get the last applied revision of the customization and to identify the source controller - Use
kubectl get gitrepositoryto get the source repository and its latest commit
In this case the command at each step depends on the output of the previous step.
Troubleshooting Workload Identity and GCP Permissions
Troubleshooting workflows are often multi-step workflows. For example, suppose we are trying to troubleshoot why a pod on a GKE cluster can’t access a GCS bucket. We might do the following
- Use kubectl to get the deployment to identify the Kubernetes service account (KSA)
- Use kubectl to get the KSA to identify and get the annotation specifying the GCP service account (GSA)
- Use
gcloud policy-troubleshoot iamto check whether the GSA has the necessary permissions to access the GCS bucket
Motivation: Verbose Responses and Chat Models
One of the problems with the existing UX is that since we use Chat models to generate completions the completions often contain markdown cells before or after the code cells. These cells correspond to the chat model providing additional exposition or context. For example if we use a cell with the text
Use gcloud to list the buckets
Foyle inserts two cells
A markdown cell
To list the buckets using `gcloud`, you can use the following command:
and then a code cell
gcloud storage buckets list
The markdown cell is redundant with the previous markdown cell and a user would typically delete it. We’d like to create a better UX where the user can more easily accept the suggested code cell and reject the markdown cell.
UX For Continuous Suggestion
As the user edits one cell (either markdown or code), we’d like Foyle to be continuously running in the background to generate one or more cells to be inserted after the current cell. This is similar to GitHub Copilot and [Continue.Dev Autocomplete](https://docs.continue.dev/walkthroughs/tab-autocomplete. An important difference is that we don’t need Foyle to autocomplete the current cell. This should simplify the problem because
- we have more time to generate completions
- the completion needs to be ready by the time the user is ready to move onto the next cell rather than before they type the next character
- we can use larger models and longer context windows since we lave a larger latency budget
- we don’t need to check that the completion is still valid after each character is typed into the current cell because we aren’t trying to auto complete the word(s) and current cell.
If we mimicked ghost text. The experience might look as follows
- User is editing cell N in the notebook
- Foyle is continuously running in the background to generate suggested cells N+1,…, N+K
- The suggested cells N+1,…,N+k are rendered in the notebook in a manner that makes it clear that they are suggestions
that haven’t been accepted or rejected yet
- Following Ghost Text we could use a grayed out font and different border for the cells
- As the user edits cell N, Foyle updates and edits N+1,…,N+K to reflect changes to its suggestions
- The decision to accept or reject the situation is triggered when the user decides to move onto cell N+1
- If the user switches focus to the suggested N+1 cell that’s considered accepting the suggestion
- If the user inserts a new cell that’s considered a rejection
- Each time Foyle generates a new completion it replaces any previous suggestions that haven’t been accepted and inserts the new suggested cells
- When the notebook is persisted unapproved suggestions are pruned and not saved
Since every notebook cell is just a TextEditor I think we can use the TextEditorDecoration API to change how text is rendered in the suggested cells to indicate they are unaccepted suggestions.
We can use Notebook Cell Metadata to keep track of cells that are associated with a particular suggestion and need to be accepted or rejected. Since metadata is just a key value store we can add a boolean “unaccepted” to indicate a cell is still waiting on acceptance.
Completion Protocol
Our existingGenerateService is a unary RPC call. This isn’t ideal for continually generating suggestions as a user updates a block. We can use the connect protocol to define a full streaming RPC call for generating suggestions. This will allow the client to stream updates to the doc to the generate service and the generate service to respond with a stream of completions.
// Generate completions using AI
service GenerateService {
// StreamGenerate is a bidirectional streaming RPC for generating completions
rpc StreamGenerate (stream StreamGenerateRequest) returns (stream StreamGenerateResponse) {}
}
message StreamGenerateRequest {
oneof request {
FullContext full_context = 1;
BlockUpdate update = 2;
}
}
message FullContext {
Doc doc = 1;
int selected = 2;
}
message BlockUpdate {
string block_id = 1;
string block_content = 2;
}
message Finish {
// Indicates whether the completion was accepted or rejected.
bool accepted = 1;
}
message StreamGenerateResponse {
repeated Block blocks = 1;
}
The stream will be initiated by the client sending a FullContext message with the full document and the index
of the current cell that is being edited. Subsequent messages will be BlockUpdates containing the full content
of the current active cell. If its a code cell it will include the outputs if the cell has been executed.
Each StreamGenerateResponse will contain a complete copy of the latest suggestion. This is simpler than
only sending and applying deltas relative to the previous response.
Client Changes
In vscode we can use the onDidChangeTextDocument to listen for changes to the a notebook cell (for more detail see appendix). We can handle this event by initializing a streaming connection to the backend to generate suggestions. On subsequent changes to the cell we can stream the updated cell contents to the backend to get updated suggestions.
We could use a rate limiting queue ( i.e. similar to workqueue but implemented in TypeScript) to ensure we don’t send too many requests to the backend. Each time the cell changes we can enqueue an event and update the current contents of the cell. We can then process the events with rate limiting enforced. Each time we process an event we’d send the most recent version of the cell contents.
Accepting or Rejecting Suggestions
We need a handler to accept or reject the suggestion. If the suggestion is accepted it would
- Update the metadata on the cells to indicate they are accepted
- Change the font rendering to indicate the cells are no longer suggestions
This could work as follows
- A suggested cell is accepted when the user moves the focus to the suggested cell
- e.g. by using the arrow keys or mouse
- If we find this a noisy signal we could consider requiring additional signals such as a user executes the code cell or for a markdown cell edits or renders it
- When the document is persisted any unaccepted suggestions would be pruned and not get persisted
- Any time a new completion is generated; any unaccepted cells would be deleted and replaced by the new suggested cells
Since each cell is a text editor, we can use onDidChangeActiveTextEditor to detect when the focus changes to a new cell and check if that cell is a suggestion and accept it if it is.
To prune the suggestions when the document is persisted we can update RunMe’s serializer to filter out any unapproved cells.
As noted in the motivation section, we’d like to create a better UX for rejecting cells containing verbose markdown response. With the proposed UX if a user skips over a suggested cell we could use that to reject earlier cells. For example, suppose cell N+1 contains verbose markdown the user doesn’t want and N+2 contains useful commands. In this case a user might use the arrow keys to quickly switch the focus to N+2. In this case, since the user didn’t render or execute N+1 we could interpret that as a rejection of N+1 and remove that cell.
The proposal also means the user would almost always see some suggested cells after the current active cell. Ideally, to avoid spamming the user with low quality suggestions Foyle would filter out low confidence suggestions and just return an empty completion. This would trigger the frontend to remove any current suggestions and show nothing.
Ghost Cells In VSCode
We’d like to render cells in VSCode so as to make it apparent they are suggestions. An obvious way to represent a Ghost Cell would be to render its contents using GhostText; i.e. greyed out text.
In VScode the NotebookDocument and NotebookCell correspond to the in memory data representation of the notebook. Importantly, these APIs don’t represent the visual representation of the notebook. Each NotebookCell contains a TextDocument representing the actual contents of the cell.
A TextEditor is the visual representation of a cell. Each TextEditor has a TextDocument. TextEditor.setDecorations
can be used to change how text is rendered in a TextEditor. We can use setDecorations to change how the contents
of a TextEditor are rendered.
TextEditors aren’t guaranteed to exist for all cells in a notebook. A TextEditor is created when a cell becomes visible and can be destroyed when the cell is no longer visible.
So we can render Ghost cells as follows
- Use metadata in
NotebookCellto indicate that a cell is a suggestion and should be rendered as a GhostCell- This will persist even if the cell isn’t visible
- Use the
onDidChangeVisibleTextEditorsto respond whenever a TextEditor is created or becomes vibile - From the
TextEditorpassed to theonDidChangeVisibleTextEditorshandler get the URI of theTextDocument- This URI should uniquely identify the cell
- Use the URI to find the corresponding
NotebookCell - Determine if the cell is a GhostCell by looking at the metadata of the cell
- If the cell is a GhostCell use
vscode.window.createTextEditorDecorationTypeto render the cell as a GhostCell
LLM Completions
The backend will generate an LLM completion in response to each StreamGenerateRequest and then return the response
in a StreamGenerateResponse. This is the simplest thing we can do but could be wasteful as we could end up
recomputing the completion even if the cell hasn’t changed sufficiently to alter the completion. In the future,
we could explore more sophisticated strategies for deciding when to compute a new completion. One simple thing
we could do is
- Tokenize the cell contents into words
- Assign each word a score measuring its information content
-log(p(w))wherep(w)is the probability of the word in the training data. - Generate a new completion each time a word with a score above a threshold is added or removed from the cell.
Multiple completions
Another future direction we could explore is generating multiple completions and then trying to rank them and select the best one. Alternatively, we could explore a UX that would make it easy to show multiple completions and let the user select the best one.
Collecting Feedback And Learning
As described in TN002 Learning and in the blog post Learning, Foyle relies on implicit human feedback to learn from its mistakes. Currently, Foyle only collects feedback when a user asks for a suggestion. By automatically generating suggestions we create more opportunities for learning and should hopefully increase Foyle’s learning rate.
We’d like to log when users accept or reject suggestions. We can introduce a new protocol to log events
service LoggingService {/
rpc Log (request LogRequest) returns (response LogResponse) {}
}
message LogRequest{
repeated CellEvent cell_events = 1;
}
enum EventType {
UNKOWN = 0;
ACCEPTED = 1;
REJECTED = 2;
EXECUTED = 3;
}
message CellEvent {
Cell cell = 1;
EventType event_type = 2;
}
message LogResponse {}
When a cell is accepted or rejected we can use the Log RPC to log it to Foyle.
One of the strongest signals we can collect is when the user rejects the completion. In this case, we’d like to log and learn from whatever code the user ends up manually entering and executing. Right now Foyle relies on RunMe’s Runner Service to log cell executions. This method only contains the executed cell and not any preceeding cells. We need those preceeding cells in order to learn.
Using the proposed logging service we can directly log when a cell is executed and include preceeding cells as context so we can retrain Foyle to better predict the code cell in the future.
Alternative Designs
Complete the current cell
The current proposal calls for “Auto-Inserting” one or more cells but not autocompleting the current cell. An alternative would be to do both simultaneously
- Autocomplete the current cell
- Auto-Insert one or more cells after the current cell
One of the reasons for not autocompleting the current cell is because GitHub copilot already does that. Below is a screen shot illustrating GitHub populating the current cell with Ghost Text containing a possible completion.

More importantly, the problem we want Foyle to turn high level expressions of intent into concrete low level actions. In this context a user edits a markdown cell to express their intent. The actions are rendered as code cells that would come next. So by focusing on generating the next code cells we are scoping the problem to focus on generating the actions to accomplish the intent rather than helping users express their intent.
By focusing on generating the next cell rather than completing the current cell we can tolerate higher latencies for completion generation than in a traditional autocomplete system. In a traditional autocomplete system you potentially want to update the completion after each character is typed leading to very tight latency requirements. In the proposal our latency bounds are determined by how long it takes the user to complete the current cell and move onto the next cell. We can take advantage of this to use larger models and longer context windows which should lead to better suggestions.
References
- Prompt for Autocomplete
- Completion Provider
- It looks like completion is a unary call and not a streaming call.
- I don’t think continue.dev has a notion of a vscode client and backend where the backend is talking to the LLM. So I don’t think it would have a streaming protocol for updating the backend as additional keys are typed.
foyle#111 Open issue about changing the prompt for fill in the midel.
Docs about implementing autocomplete
VSCode
- VSCode GitHub Chat API
- I think using the VSCode Chat API to contribute a participant still requires GitHub Copilot
- VSCode Extension API
- VSCode Extension Comment Controller Sample
- VSCode has a comment controller API which could potentially be used to allow commenting on cells as a way of interacting with the AI
- Discord Thread
How does LLM triggering work in Autocomplete
Typically in autocomplete you are completing the stream of characters a user is typing. So as each character is added it could invalidate one or more completions. For example if the user enters the character “n” possible completions are “news…”, “normal…”, etc… When the user enters the next character “ne” we’d like to immediately update the ranking of completions and reject any that are no longer valid.
One way to handle this is each time you generate a completion you could ask the LLM to generate multiple completions (e.g. [OpenAI]’s n parameter)(https://platform.openai.com/docs/api-reference/chat/create). These completions should represent the most likely completions given the current input. Each additional character can then be used to invalidate any suggestions that don’t match.
Appendix: VSCode Background
This section provides information about how VSCode extensions and notebooks work. It is relevant for figuring out how to implement the extension changes.
In VSCode notebooks each cell is just a discrete text editor (discord thread). VScode’s extension API is defined here.
The onDidChangeTextDocument fires when the text in a document changes. This could be used to trigger the AI to generate suggestions.
As described in vscode_apis Notebooks have a data API ((NotebookData, NotebookCellData) and and editor API(NotebookDocument, NotebookCell). NotebookCell contains a TextDocument which we should be able to use to listen for onDidChangeTextDocument events.
I think you can register a handler that will fire for changes to any TextDocument change and not just for a particular
cell. The document URI should use the vscode-notebook-cell scheme and allow us to identify the notebook document
and cell that changed (code example).
TextDecorations
TextDecorations are properties of TextEditors. Each NotebookCell is a different TextEditor. TextEditors get created for a NotebookCell when the cell becomes visible and can be destroyed when the cell is deleted.
7.9 - TN009 Review AI in Notebooks
Objective
- Review how other products/projects are creating AI enabled experiences in a notebook UX
TL;DR
There are lots of notebook products and notebook like interfaces. This doc tries to summarize how they are using AI to enhance the notebook experience. The goal is to identify features and patterns that could be useful incorporating into Foyle and RunMe.
JupyterLab AI
JupyterLab AI is a project that aims to bring AI capabilities to JupyterLab. It looks like it introduces a couple ways of interacting with AI’s
- GitHub copilot like chat window docs.
- AI Magic Commands
- Inline Completer uses ghost text to render completions to the current cell
The chat feature looks very similar to GitHub copilot chat. Presumably its more aware of the notebook structure. For example, it lets you select notebook cells and include them in your prompt (docs).
Chat offers built in RAG. Using the /learn command you can inject a bunch of documents into a datastore. These documents are then used to answer questions in the chat using RAG.
The AI magic commands let you directly invoke different AI models. The prompt is the text inside the cell. The model output is then rendered in a new cell. This is useful if your asking the model to produce code because you can then execute the code in the notebook.
In RunMe you achieve much of the same functionality as the magics by using a CLI like llm and just executing that in a bash cell.
Compared to what’s proposed in TN008 Autocompleting cells it looks like the inline completer only autocompletes the current cell; it doesn’t suggest new cells.
JupyterLab AI Links
Hex
Hex magic lets you describe in natural language what you want to do and then it adds the cells to the notebook to do that. For example, you can describe a graph you want and it will add an SQL cell to select the data Demo Video.
Notably, from a UX perspective prompting the AI is a “side conversation”. There is a hover window that lets you ask the AI to do something and then the AI will modify the notebook accordingly. For example, in their Demo Video you explicitly ask the AI to “Build a cohort analysis to look at customer churn”. The AI then adds the cells to the notebook. This is different from an AutoComplete like UX as proposed in TN008 Autocompleting cells.
In an Autocomplete like UX, a user might add a markdown cell containing a heading like “Customer Churn: Cohort Analysis”. The AI would then autocomplete these by inserting the cells to perform the analysis and render it. The user wouldn’t have to explicitly prompt the AI.
7.10 - TN010 Level 1 Evaluation
Objective:
Design level 1 evaluation to optimize responses for AutoComplete
TL;DR
As we roll out AutoComplete we are observing that AI quality is an issue jlewi/foyle#170. Examples of quality issues we are seeing are
- AI suggests a code cell rather than a markdown cell when a user is editing a markdown cell
- AI splits commands across multiple code cells rather than using a single code cell
We can catch these issues using Level 1 Evals which are basically assertions applied to the AI responses.
To implement Level 1 Evals we can do the following
- We can generate an evaluation from logs of actual user interactions
- We can create scripts to run the assertions on the AI responses
- We can use RunMe to create playbooks to run evaluations and visualize the results as well as data
Background:
Existing Eval Infrastructure
TN003 described how we could do evaluation given a golden dataset of examples. The implementation was motivated by a number of factors.
We want a resilient design because batch evaluation is a long running, flaky process because it depends on an external service (i.e. the LLM provider). Since LLM invocations cost money we want to avoid needlessly recomputing generations if nothing had changed. Therefore, we want to be able to checkpoint progress and resume from where we left off.
We want to run the same codepaths as in production. Importantly, we want to reuse logging and visualization tooling so we can inspect evaluation results and understand why the AI succeeded.
To run experiments, we need to modify the code and deploy a new instance of Foyle just for evaluation. We don’t want the evaluation logs to be mixed with the production logs; in particular we don’t want to learn from evaluation data.
Evaluation was designed around a controller pattern. The controller figures out which computations need to be run for each data point and then runs them. Thus, once a data point is processed, rerunning evaluation becomes a null-op. For example, if an LLM generation has already been computed, we don’t need to recompute it. Each data point was an instance of the EvalResult Proto. A Pebble Database was used to store the results.
Google Sheets was used for reporting of results.
Experiments were defined using the Experiment Resource via YAML files. An experiment could be run using the Foyle CLI.
Defining Assertions
As noted in Your AI Product Needs Evals we’d like to design our assertions so they can be run online and offline.
We can use the following interface to define assertions
type Assertion interface {
Assert(ctx context.Context, doc *v1alpha1.Doc, examples []*v1alpha1.Example, answer []*v1alpha1.Block) (AssertResult, error)
// Name returns the name of the assertion.
Name() string
}
type AssertResult string
AssertPassed AssertResult = "passed"
AssertFailed AssertResult = "failed"
AssertSkipped AssertResult = "skipped"
The Assert method takes a document, examples, and the AI response and returns a triplet indicating whether the assertion passed
or was skipped. Context can be used to pass along the traceId of the actual request.
Online Evaluation
For online execution, we can run the assertions asynchronously in a thread. We can log the assertions using existing logging patterns. This will allow us to fetch the assertion results as part of the trace. Reporting the results should not be the responsibility of each Assertion; we should handle that centrally. We will use OTEL to report the results as well; each assertion will be added as an attribute to the trace. This will make it easy to monitor performance over time.
Batch Evaluation
For quickly iterating on the AI, we need to be able to do offline, batch evaluation. Following
the existing patterns for evaluation, we can define a new AssertJob resource to run the assertions.
kind: AssertJob
apiVersion: foyle.io/v1alpha1
metadata:
name: "learning"
spec:
sources:
- traceServer:
address: "http://localhost:8080"
- mdFiles:
path: "foyle/evalData"
# Pebble database used to store the results
dbDir: /Users/jlewi/foyle_experiments/20250530-1612/learning
agent: "http://localhost:108080"
sheetID: "1iJbkdUSxEkEX24xMH2NYpxqYcM_7-0koSRuANccDAb8"
sheetName: "WithRAG"
The source field specifies the sources for the evaluation dataset. There are two different kinds of sources. A traceServer
specifies an instance of a Foyle Agent that makes its traces available via an API. This can be used to generate examples
based on actual user interactions. The Traces need to be read via API and not directly from the pebble database because the pebble database is not designed for concurrent access.
The mdFiles field allows examples to be provided as markdown files. This will be used to create a handcrafted curated
dataset of examples.
The Agent field specifies the address of the instance of Foyle to be evaluated. This instance should be configured to store its data in a different location.
The SheetID and SheetName fields specify the Google Sheet where the results will be stored.
To perform the evaluation, we can implement a controller modeled on our existing Evaluator.
Traces Service
We need to introduce a Trace service to allow the evaluation to access traces.
service TracesService {
rpc ListTraces(ListTracesRequest) returns (ListTracesResponse) {
}
}
We’ll need to support filtering and pagination. The most obvious way to filter would be on time range. A crude way to support time based filtering would be as follows
- Raw log entries are written in timestamp order
- Use the raw logs to read log entries based on time range
- Get the unique set of TraceIDs in that time range
- Look up each trace in the traces database
Initial Assertions
Here are some initial assertions we can define
- If human is editing a markdown cell, suggestion should start with a code cell
- The response should contain one code cell
- Use regexes to check if interactive metadata is set correctly jlewi/foyle#157
- interactive should be false unless the command matches a regex for an interactive command e.g. “kubectl.exec.”, “docker.run.” etc…
- Ensure the AI doesn’t generate any cells for empty input
Reference
Your AI Product Needs Evals Blog post describing the Level 1, 2, and 3 evals.
7.11 - TN011 Building An Eval Dataset
Objective
- Design a solution for autobuilding an evaluation dataset from logs
TL;DR
An evaluation dataset is critical for being able to iterate quickly. Right now cost is a major concern because Ghost Cells use a lot of tokens due to a naive implementation. There are a number of experiments we’d like to run to see if we can reduce cost without significantly impacting quality.
One way to build an evaluation dataset is from logs. With the recent logging changes, we introduced a concept of sessions. We can use sessions to build an evaluation dataset.
Sessionization Pipeline
The frontend triggers a new session whenever the active text editor changes. When the activeEditor changes the frontend sends a LogEvent closing the current session and starting a new one. The sessionId is included in requests, e.g. StreamGenerate, using the contextId parameter. Each time a stream is initiated, the initial request should include the notebook context.
If the active editor is a code cell and it is executed the frontend will send a LogEvent recording execution.
The streaming log processor can build up sessions containing
- Context
- Executed cell
We could then use the context as the input and the executed cell as the ground truth data. We could then experiment by how well we do predicting the executed cell.
How Do We Handle RAG
Foyle learns from feedback. Foyle adaptively builds up a database of example (input, output) pairs and uses them to prompt the model. The dataset of learned examples will impact the model performance significantly. When we do evaluation we need to take into account this learning.
Since we are building the evaluation dataset from actual notebooks/prompts there is an ordering to the examples. During evaluation we can replay the sessions in the same order they occured. We can then let Foyle adaptively build up its learned examples just as it does in production. Replaying the examples in order ensures we don’t pollute evaluation by using knowledge of the furture to predict the past.
LLM As Judge
Lots of code cells don’t contain single binary invocations but small minny programs. Therefore, the similarity metric proposed in TN003 won’t work. We can use LLM as judge to decide whether the predicted and actual command are equivalent.
7.12 - TN012 Why Does Foyle Cost So Much
Objective
- Understand Why Foyle Costs So Much
- Figure out how to reduce the costs
TL;DR
Since enabling Ghost and upgrading to Sonnet 3.5 and GPT40 Cells, Foyle has been using a lot of tokens.
We need to understand why and see if we can reduce the cost without significantly impacting quality. In particular, there are two different drivers of our input tokens
- How many completions we generate for a particular context (e.g. as a user types)
- How much context we include in each completion
Analysis indicates that we are including way too much context in our LLM requests and can reduce it by 10x to make the costs more manageable. An initial target is to spend ~$.01 per session. Right now sessions are costing beteen $0.10 and $0.30.
Background
What is a session
The basic interaction in Foyle is as follows:
User selects a cell to begin editing
- In VSCode each cell is a text editor so this corresponds to changing the active text editor
A user starts editing the cell
As the user edits the cell (e.g. types text), Foyle generates suggested cells to insert based on the current context of the cell.
- The suggested cells are inserted as ghost cells
User switches to a different cell
We refer to the sequence of events above as a session. Each session is associated with a cell that the user is editing. The session starts when the user activates that cell and the session ends when the user switches to a different cell.
How Much Does Claude Cost
The graph below shows my usage of Claude over the past month.
 Figure 1. My Claude usage over the past month. The usage is predominantly from Foyle although there are some other minor usages (e.g. with Continue.dev). This is for Sonnet 3.5 which is $3 per 1M input tokens and $15 per 1M output tokens.
Figure 1. My Claude usage over the past month. The usage is predominantly from Foyle although there are some other minor usages (e.g. with Continue.dev). This is for Sonnet 3.5 which is $3 per 1M input tokens and $15 per 1M output tokens.
Figure 1. Shows my Claude usage. The cost breakdown is as follows.
| Type | # Tokens | Cost |
|---|---|---|
| Input | 16,209,097 | $48.6 |
| Output | 337,018 | $4.5 |
So cost is dominated by input tokens.
Cost Per Session
We can use the query below to show the token usage and cost per session.
sqlite3 -header /Users/jlewi/.foyle/logs/sessions.sqllite3 "
SELECT
contextid,
total_input_tokens,
total_output_tokens,
num_generate_traces,
total_input_tokens/1E6 * 3 as input_tokens_cost,
total_output_tokens/1E6 * 15 as output_tokens_cost
FROM sessions
WHERE total_input_tokens > 0 OR total_output_tokens > 0 OR num_generate_traces > 0
ORDER BY contextId DESC;
"
| contextID | total_input_tokens | total_output_tokens | num_generate_traces | input_tokens_cost | output_tokens_cost |
|---|---|---|---|---|---|
| 01J83RZGPCJ7FJKNQ2G2CV7JZV | 121105 | 1967 | 24 | 0.363315 | 0.029505 |
| 01J83RYPHBK7BG51YRY3XC2BDC | 31224 | 967 | 6 | 0.093672 | 0.014505 |
| 01J83RXH1R6QD37CQ20ZJ61637 | 92035 | 1832 | 20 | 0.276105 | 0.02748 |
| 01J83RWTGYAPTM04BVJF3KCSX5 | 45386 | 993 | 11 | 0.136158 | 0.014895 |
| 01J83R690R3JXEA1HXTZ9DBFBX | 104564 | 1230 | 12 | 0.313692 | 0.01845 |
| 01J83QG8R39RXWNH02KP24P38N | 115492 | 1502 | 17 | 0.346476 | 0.02253 |
| 01J83QEQZCCVWSSJ9NV57VEMEH | 45586 | 432 | 6 | 0.136758 | 0.00648 |
| 01J83ACF7ARHVMQP9RG2DTT49F | 43078 | 361 | 6 | 0.129234 | 0.005415 |
| 01J83AAPT28VM05C90GXS8ZRBT | 19151 | 132 | 5 | 0.057453 | 0.00198 |
| 01J83AA5P4XT6Z0XB40DQW572A | 38036 | 615 | 6 | 0.114108 | 0.009225 |
| 01J838F559V97NYAFS6FZ2SBNA | 29733 | 542 | 6 | 0.089199 | 0.00813 |
Table 1. Results of measuring token usage and cost per session on some of my recent queries.
The results in Table 1. indicate that the bigger win is likely to come from reducing the amount of context and thus token usage rather than reducing the number of completions generated. Based on table 1 it looks like we could at best reduce the number of LLM calls by 2x-4x. For comparison, it looks like input token is typically 100x our output tokens. Since we ask the model to generate a single code block (although it may generate more), we can use the output tokens as a rough estimate of the number of tokens in a typical cell. This suggests we are using ~10-100 cells of context for each completion. This is likely way more than we need.
Discussion
Long Documents
I think the outliers in the results in Table 1, e.g. 01J83RZGPCJ7FJKNQ2G2CV7JZV which cost $.36,
can be explained by long documents. I use a given markdown document to take running notes on a topic.
So the length of the document can grow quite long leading to a lot of context being sent to Claude.
In some cases, earlier portions of the document are highly relevant. Consider the following sequence of actions:
- I come up with a logging query to observe some part of the system
- The result shows something surprising
- I run a bunch of commands to investigate whats happening
- I want to rerun the logging query
In this case, the cell containing the earlier query can provide useful context for the current query.
Including large portions of the document may not be the most token efficient way to make that context available to the model. In Foyle since learning happens online, relying on learning to index the earlier cell(s) and retrieve the relevant ones might be a more cost effective mechanism than relying on a huge context window.
How much context should we use?
If we set a budget for sessions than we can use that to put a cap on the number of input tokens.
Lets assume we want to spend ~ $.01 on input tokens per session. This suggests we should use ~3333 input tokens per session.
If we assume ~6 completions per session then we should use a max of ~555 input tokens per completion.
We currently limit the context based on characters to 16000 which should be ~8000 tokens (assuming 1 token = 2 characters)
num_generate_traces with outliers
A cell with a really high number of completions (e.g. 24) is likely to be a cell that a user spends a long time writing. For me at least, these cells tend to correspond to cells where I’m writing exposition and not necessarily expressing intents that should be turned into commands. So in the future we might want to consider how to detect this and limit completion generation in those calls.
Less Tokens -> More completions
Right now our algorithm for deciding when to initiate a new completion in a session is pretty simple. If the cell contents have changed then we generate a new completion as soon as the current running completion finishes. Reducing input tokens will likely make generations faster. So by reducing input tokens we might increase the average number of completions per session which might offset some of the cost reductions due to fewer input tokens.
Appendix: Curious Result - Number Of Session Starts
In the course of this analysis I observed the surprising result that the number of session starts is higher than the number StreamGenerate events.
We can use logs to count the number of events in a 14 day window.
| Event Type | Count |
|---|---|
| Session Start | 792 |
| Agent.StreamGenerate | 332 |
| Agent.Generate | 1487 |
I’m surprised that the number of Session Start events is higher than the number of Agent.StreamEvents. I would have expected Agent.StreamGenerate to be higher than Session Start since for a given session the stream might be recreated multiple times (e.g. due to timeouts). A SessionStart is reported when the active text editor changes. A stream should be created when the cell contents change. So the data implies that we switch the active text editor without changing the cell contents.
The number of Agent.Generate events is ~4.5x higher than Agent.StreamGenerate. This means on average we do at least 4.5 completions per session. However, a session could consist of multiple StreamGenerate requests because the stream can be interrupted and restarted; e.g. because of timeouts.
7.13 - TN013 Improve Learning
Objective
- Learn from all executed cells not just generated cells
TL;DR
Today, learning only occurs in a small fraction of cases. In particular, the following must be true for learning to occur
- Code cell was generated from AI
- User edited the code cell
This limitation was the result of relying on the GenerateRequest to log the notebook to be used as input.
We now have the LogEvents API and log the full notebook each time the cell focus changes. We also LogEvents corresponding to cell executions. This means we can use any cell execution (regardless of how it was generated) to learn. We also log the cell execution status so we can avoid learning from failed executions.
Background
How does learning work today
The Analyzer is a stream processor for the logs that produces blocklogs. When the Analyzer, encounters an Execute event it enqueues the BlockLog for processing in the learner (here).
The Learner then checks whether the BlockLog meets various criterion for learning e.g.
- Was the block generated via AI?
- Is the generated block different from the text that was actually executed?
Importantly, in order to do learning we need to know the block (cell) that was produced and the cells that preceded it which should be considered the input to the AI.
Currently, the context is obtained via the GenerateRequest. The analyzer builds a GenerateTrace. For each block that gets produced by the trace, the corresponding block log is updated with the ID of the trace.
Analyzer.buildBlockLog fetches the Generate trace and uses it to populate BlockLog.Doc with the cells that preceded the doc.
When we originally implemented learning, the GenerateRequest was the only mechanism we had for recording the doc. This was one of the reasons we could only do learning if the cell was generated by AI. Learning was originally implemented before we had ghost cells and were automatically requesting completions. In this case, a generate request had to be explicitly triggered by the user.
We now have the LogEvents RPC which sends a session start event whenever we activate a cell. This will include the full context. A session also contains events for cell execution. Cell execution events include
- Actual cell executed
- Cell execution status
All sessions should include a session end event. The session end event however doesn’t include any cells.
I believe the motivation for only learning if the user edited an AI suggestion was to improve RAG. If the model was already accurately predicting a cell, then there was no reason to add another example of it to our database.
Proposal: Learn Based on Sessions
The SessionProto has most of the data we need. A session corresponds to all the edits of a cell. For a code cell
- FullContext provides a full copy of the notebook when focus was placed on a cell
- Execution event will contain the executed cell
- To test if the cell was AI generated we could fetch the BlockLog for the cell
For a markdown cell
- FullContext provides a full copy of the notebook when focus was placed on a cell
- We don’t have a copy of the cell but we could obtain it a couple ways
- The sesion that starts next will have the full context which includes the final version of the cell
- The LogEvent reports session end and start in the same event so we could link sessions on the backend
In the case of AI generated cells, we no longer require the user to have edited the cell in order to trigger learning. Dropping this restriction simplifies the learning logic since we don’t have to check whether a cell was AI generated and whether it was edited.
Future Directions
In the future we’d like to extend learning to work for non-code cells.