Without a copilot for devops we won't keep up
Since co-pilot launched in 2021, AI accelerated software development has become the norm. More importantly, as Simon Willison argued at last year’s AI Engineer Summit with AI there has never been an easier time to learn to code. This means the population of people writing code is set to explode. All of this begs the question, who is going to operate all this software? While writing code is getting easier, our infrastructure is becoming more complex and harder to understand. Perhaps we shouldn’t be surprised that as the cost of writing software decreases, we see an explosion in the number of tools and abstractions increasing complexity; the expanding CNCF landscape is a great illustration of this.
The only way to keep up with AI assisted coding is with AI assisted operations. While we are being flooded with copilots and autopilots for writing software, there has been much less progress with assistants for operations. This is because 1) everyone’s infrastructure is different; an outcome of the combinatorial complexity of today’s options and 2) there is no single system with a complete and up to date picture of a company’s infrastructure.
Consider a problem that has bedeviled me ever since I started working on Kubeflow; “I just want to deploy Jupyter on my company’s Cloud and access it securely.” To begin to ask AIs (ChatGPT, Claude, Bard) for help we need to teach them about our infrastructure; e.g. What do we use for compute, ECS, GKE, GCE? What are we using for VPN; tailscale, IAP, Cognito? How do we attach credentials to Jupyter so we can access internal data stores? What should we do for storage; Persistent disk or File store?
The fundamental problem is mapping a user’s intent, “deploy Jupyter”, to the specific set of operations to achieve that within our organization. The current solution is to build platforms that create higher level abstractions that hopefully more closely map to user intent while hiding implementation details. Unfortunately, building platforms is expensive and time consuming. I have talked to organizations with 100s of engineers building an internal developer platform (IDP).
Foyle is an OSS project that aims to simplify software operations with AI. Foyle uses notebooks to create a UX that encourages developers to express intent as well as actions. By logging this data, Foyle is able to build models that predict the operations needed to achieve a given intent. This is a problem which LLMs are unquestionably good at.
Demo
Let’s consider one of the most basic operations; fetching the logs to understand why something isn’t working. Observability is critical but at least for me a constant headache. Each observability tool has their own hard to remember query language and queries depend on how applications were instrumented. As an example, Hydros is a tool I built for CICD. To figure out whether hydros successfully built an image or hydrated some manifests I need to query its logs.
A convenient and easy way for me to express my intent is with the query
fetch the hydros logs for the image vscode-ext
If we send this to an AI (e.g. ChatGPT) with no knowledge of our infrastructure we get an answer which is completely wrong.
hydros logs vscode-ext
This is a good guess but wrong because my logs are stored in Google Cloud Logging. The correct query executed using gcloud is the following.
gcloud logging read 'logName="projects/foyle-dev/logs/hydros" jsonPayload.image="vscode-ext"' --freshness=1d --project=foyle-dev
Now the very first time I access hydros logs I’m going to have to help Foyle understand that I’m using Cloud Logging and how hydros structures its logs; i.e. that each log entry contains a field image with the name of the image being logged. However, since Foyle logs the intent and final action it is able to learn. The next time I need to access logs if I issue a query like
show the hydros logs for the image caribou
Foyle responds with the correct query
gcloud logging read 'logName="projects/foyle-dev/logs/hydros" jsonPayload.image="caribou"' --freshness=1d --project=foyle-dev
I have intentionally asked for an image that doesn’t exist because I wanted to test whether Foyle is able to learn the correct pattern as opposed to simply memorizing commands. Using a single example Foyle learns 1) what log is used by hydros and 2) how hydros uses structured logging to associate log messages with a particular image. This is possible because foundation models already have significant knowledge of relevant systems (i.e. gcloud and Cloud Logging).
Foyle relies on a UX which prioritizes collecting implicit feedback to teach the AI about our infrastructure.

In this interaction, a user asks an AI to translate their intent into one or more tools the user can invoke. The tools are rendered in executable, editable cells inside the notebook. This experience allows the user to iterate on the commands if necessary to arrive at the correct answer. Foyle logs these iterations (see this previous blog post for a detailed discussion) so it can learn from them.
The learning mechanism is quite simple. As denoted above we have the original query, Q, the initial answer from the AI, A, and then the final command, A’, the user executed. This gives us a triplet (Q, A, A’). If A=A’ the AI got the answer right; otherwise the AI made a mistake the user had to fix.
The AI can easily learn from its mistakes by storing the pairs (Q, A’). Given a new query Q* we can easily search for similar queries from the past where the AI made a mistake. Matching text based on semantic similarity is one of the problems LLMs excel at. Using LLMs we can compute the embedding of Q and Q* and measure the similarity to find similar queries from the past. Given a set of similar examples from the past {(Q1,A1’),(Q2,A2’),…,(Qn,An’)} we can use few shot prompting to get the LLM to learn from those past examples and answer the new query correctly. As demonstrated by the example above this works quite well.
This pattern of collecting implicit human feedback and learning from it is becoming increasingly common. Dosu uses this pattern to build AIs that can automatically label issues.
An IDE For DevOps
One of the biggest barriers to building copilots for devops is that when it comes to operating infrastructure we are constantly switching between different modalities
- We use IDEs/Editors to edit our IAC configs
- We use terminals to invoke CLIs
- We use UIs for click ops and visualization
- We use tickets/docs to capture intent and analysis
- We use proprietary web apps to get help from AIs
This fragmented experience for operations is a barrier to collecting data that would let us train powerful assistants. Compare this to writing software where a developer can use a single IDE to write, build, and test their software. When these systems are well instrumented you can train really valuable software assistants like Google’s DIDACT and Replit Code Repair.
This is an opportunity to create a better experience for devops even in the absence of AI. A great example of this is what the Runme.dev project is doing. Below is a screenshot of a Runme.dev interactive widget for VMs rendered directly in the notebook.
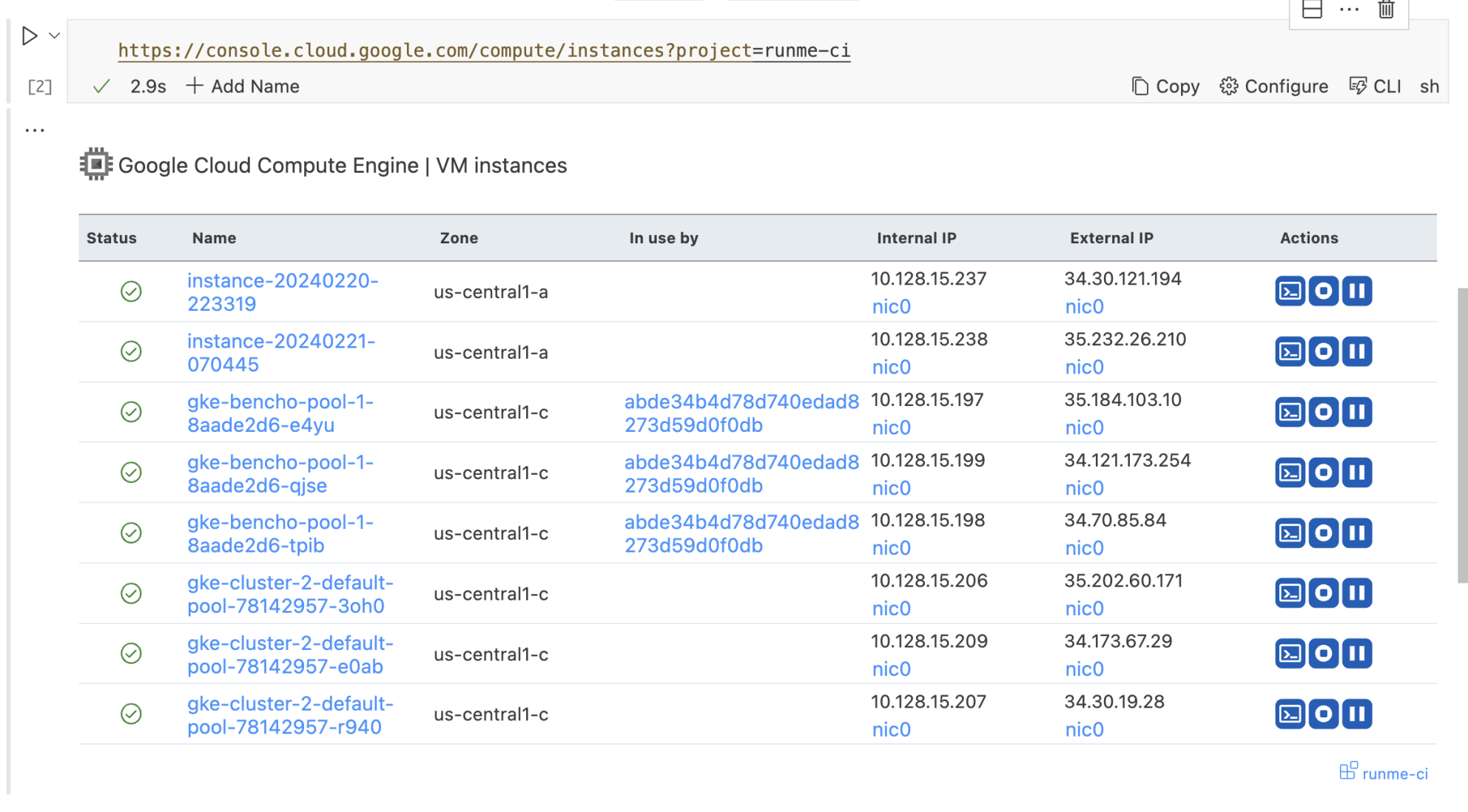
This illustrates a UX where users don’t need to choose between the convenience of ClickOps and being able to log intent and action. Another great example is Datadog Notebooks. When I was at Primer, I found using Datadog notebooks to troubleshoot and document issues was far superior to copying and pasting links and images into tickets or Google Docs.
Conclusion: Leading the AI Wave
If you’re a platform engineer like me you’ve probably spent previous waves of AI building tools to support AI builders; e.g. by exposing GPUs or deploying critical applications like Jupyter. Now we, platform engineers, are in a position to use AI to solve our own problems and better serve our customers. Despite all the excitement about AI, there’s a shortage of examples of AI positively transforming how we work. Let’s make platform engineering a success story for AI.
Acknowledgements
I really appreciate Hamel Husain reviewing and editing this post.