Overview
What is Foyle?
Foyle is an AI assistant integrated with VS Code notebooks, through the Runme extension. It helps you deploy and operate your application by letting you express your intent in natural language and then using AI to generate the commands to achieve that intent.
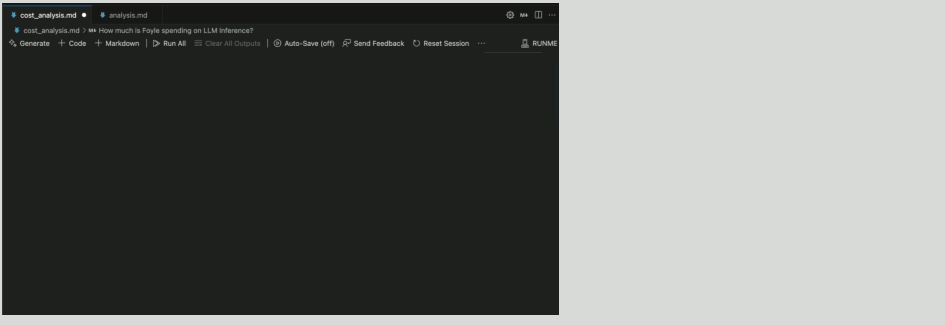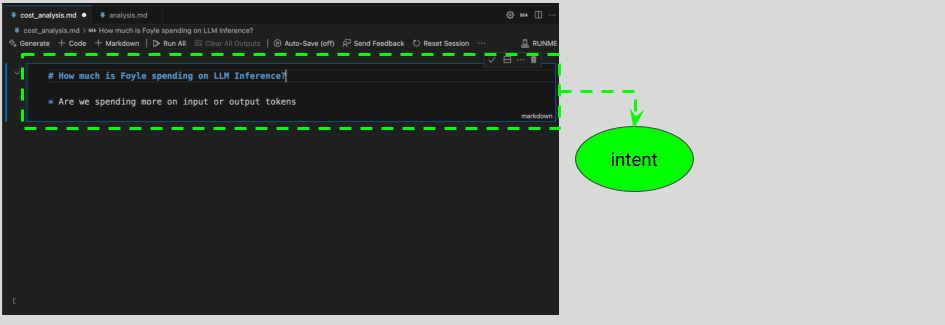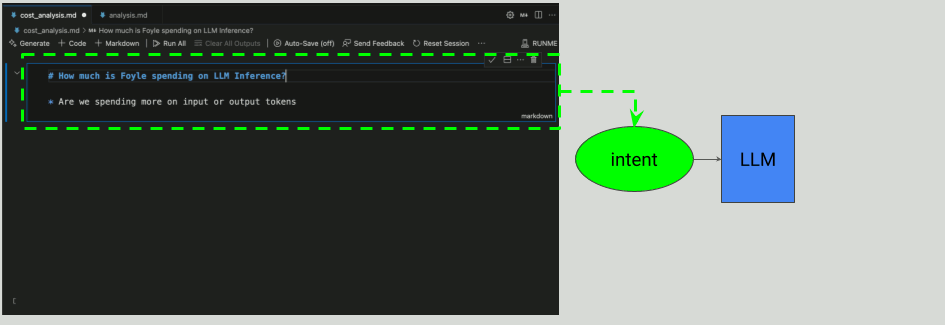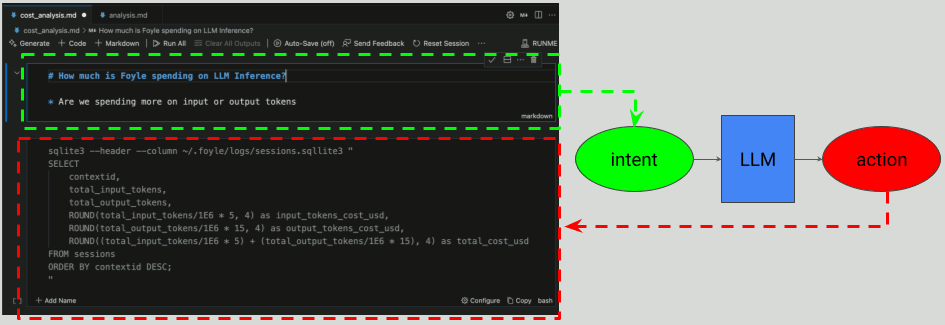
Why use Foyle?
- You struggle to remember complex commands and want to offload this problem to an AI
- You are tired of copy/pasting commands from ChatGPT/Claude/Bard into your shell
- You value documentation and want to produce markdown documents that capture
- The problem or question you are trying to solve
- The commands you ran to solve the problem
- The output of those commands
- Your analysis and conclusions
Who is Foyle for?
If your building or operating software, Foyle can help you. If your an individual developer, you can deploy Foyle locally. If you are a team, you can deploy Foyle on Kubernetes so that you have a shared AI that spreads knowledge among the team.
How much does Foyle cost?
Foyle itself is free to use. You will need to pay for your LLM usage by providing an API key or deploying your own LLM.
Where should I go next?
- Getting Started: Get started with $project
- FAQ: Frequently asked questions
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.